Domain-Driven Design Handbook
Abstract class
- An abstract class is one which defines an interface, but does not necessarily provide implementations for all its member functions.
- An abstract class is meant to be used as the base class from which other classes are derived.
- The derived class is expected to provide implementations for the member functions that are not implemented in the base class.
- A derived class that implements all the missing functionality is called a concrete class .
- Unlike concrete classes, we cannot directly instantiate an abstract class or an interface. Declaring a class as abstract means that you do not want it to be instantiated and that the class can only be inherited. You are imposing a rule in your code.
Abstract factory
The abstract factory pattern provides a way to encapsulate a group of individual factories that have a common theme without specifying their concrete classes.
This can help delegate the single responsibility of object creation to one place.
Actors
- Actors: Who or what is this relevant person (or thing) to the domain? - Authors, Editors, Guest, Server
- Commands: What can they do? - CreateUser, DeleteAccount, PostArticle
- Event: Past-tense version of the command (verb) - UserCreated, AccountDeleted, ArticlePosted
- Subscriptions: Classes that are interested in the domain event that want to be notified when they occurred - AfterUserCreated, AfterAccountDeleted, AfterArticlePosted
Aggregate
An aggregate defines a consistency boundary (by following consistency rules) around one or more entities.
An "aggregate" is a cluster of associated objects that we treat as a unit for the purpose of data changes." - Evans. 126
There are three main boundaries for aggregates:
- Transaction boundaries
- Distribution boundaries
- Concurrency boundaries
An aggregate is a collection of entities that are bound together by an aggregate root. The aggregate root is the thing that we refer to for lookups. No members from within the aggregate boundary can be referred to directly from anything external to the aggregate. This is how the aggregate maintains consistency.
The main responsibility of an aggregate is to enforce invariants across state changes for all the entities within that aggregate. The most powerful part about aggregates is that they dispatch Domain Events which can be used to co-locate business logic in the appropriate subdomain.
The most powerful part about aggregates is that they dispatch Domain Events which can be used to co-locate business logic in the appropriate subdomain.
An aggregate is not:
- Just a graph of entities
- Merely a behaviour rich object
- An entity or collection of entities that you can dump into your database tables
An aggregate represents a transactional boundary since it is responsible for keeping business invariants inviolated at any given time. Let’s take a chat application as an example. Users send messages, and users can like messages. An obvious invariant states that a user can’t like a deleted message. This invariant could be violated if a user likes a message when in the meantime the message’s owner is deleting it. This use case could be made possible if we were deleting a Message aggregate while saving a Like aggregate referencing this message. By creating a Message aggregate holding a list of the Like entities, we can no longer violate this rule because, in both “deletion” and “like” case, we act on the same Message in the database. The transaction started when the message’s owner deletes the message would prevent the transaction from “liking” the message to be started. Thus, only the aggregates can be retrieved from and saved to the database.
An aggregate might consist of a single entity, without child entities. What makes it an aggregate is the transactional boundary.
Discovering Aggregates
When trying to discover the Aggregates in a Bounded Context (2), we must understand the model’s true invariants. Only with that knowledge can we determine which objects should be clustered into a given Aggregate.
An invariant is a business rule that must always be consistent. There are different kinds of consistency. One is transactional consistency, which is considered immediate and atomic. There is also eventual consistency. When discussing invariants, we are referring to transactional consistency. We might have the invariant
c = a + b
Therefore, when a is 2 and b is 3, c must be 5. According to that rule and conditions, if c is anything but 5, a system invariant is violated. To ensure that c is consistent, we design a boundary around these specific attributes of the model:
type AggregateType1 {
a: number
b: number
c: number
function1()
function2()
...
}
The consistency boundary logically asserts that everything inside adheres to a specific set of business invariant rules no matter what operations are performed. The consistency of everything outside this boundary is irrelevant to the Aggregate. Thus, Aggregate is synonymous with transactional consistency boundary. (In this limited example, AggregateType1 has three attributes of type number, but any given Aggregate could hold attributes of various types.)
When employing a typical persistence mechanism, we use a single transaction2 to manage consistency. When the transaction commits, everything inside one boundary must be consistent. A properly designed Aggregate is one that can be modified in any way required by the business with its invariants completely consistent within a single transaction. And a properly designed Bounded Context modifies only one Aggregate instance per transaction in all cases. What is more, we cannot correctly reason on Aggregate design without applying transactional analysis.
Limiting modification to one Aggregate instance per transaction may sound overly strict. However, it is a rule of thumb and should be the goal in most cases. It addresses the very reason to use Aggregates.
The fact that Aggregates must be designed with a consistency focus implies that the user interface should concentrate each request to execute a single command on just one Aggregate instance. If user requests try to accomplish too much, the application will be forced to modify multiple instances at once.
Therefore, Aggregates are chiefly about consistency boundaries and not driven by a desire to design object graphs. Some real-world invariants will be more complex than this. Even so, typically invariants will be less demanding on our modeling efforts, making it possible to design small Aggregates.
Aggregate Root
The Root Entity of each Aggrefate owns all the other elements clustered inside it.
The name of the Root Entity is the Aggregate's conceptual name.
It is the root entity in an aggregate
Exactly one entity in an aggregate is the root.
Lookup is done using the root entity's identifier
Any other entities in the aggregate are children of the root, and are referenced by following pointers from the root.
Anti-corruption layer
- A boundary to protect the domain from external or legacy system's data schema or API.
Implement a façade or adapter layer between different subsystems that don't share the same semantics. Implement a façade or adapter layer between different subsystems that don't share the same semantics. This layer translates requests that one subsystem makes to the other subsystem. Use this pattern to ensure that an application's design is not limited by dependencies on outside subsystems. This pattern was first described by Eric Evans in Domain-Driven Design.
Problem
Most applications rely on other systems for some data or functionality. Often these legacy systems suffer from quality issues such as convoluted data schemas or obsolete APIs. Maintaining access between new and legacy systems can force the new system to adhere to at least some of the legacy system's APIs or other semantics. When these legacy features have quality issues, supporting them "corrupts" what might otherwise be a cleanly designed modern application.
Similar issues can arise with any external system that your development team doesn't control, not just legacy systems.
Solution
Isolate the different subsystems by placing an anti-corruption layer between them. This layer translates communications between the two systems, allowing one system to remain unchanged while the other can avoid compromising its design and technological approach.
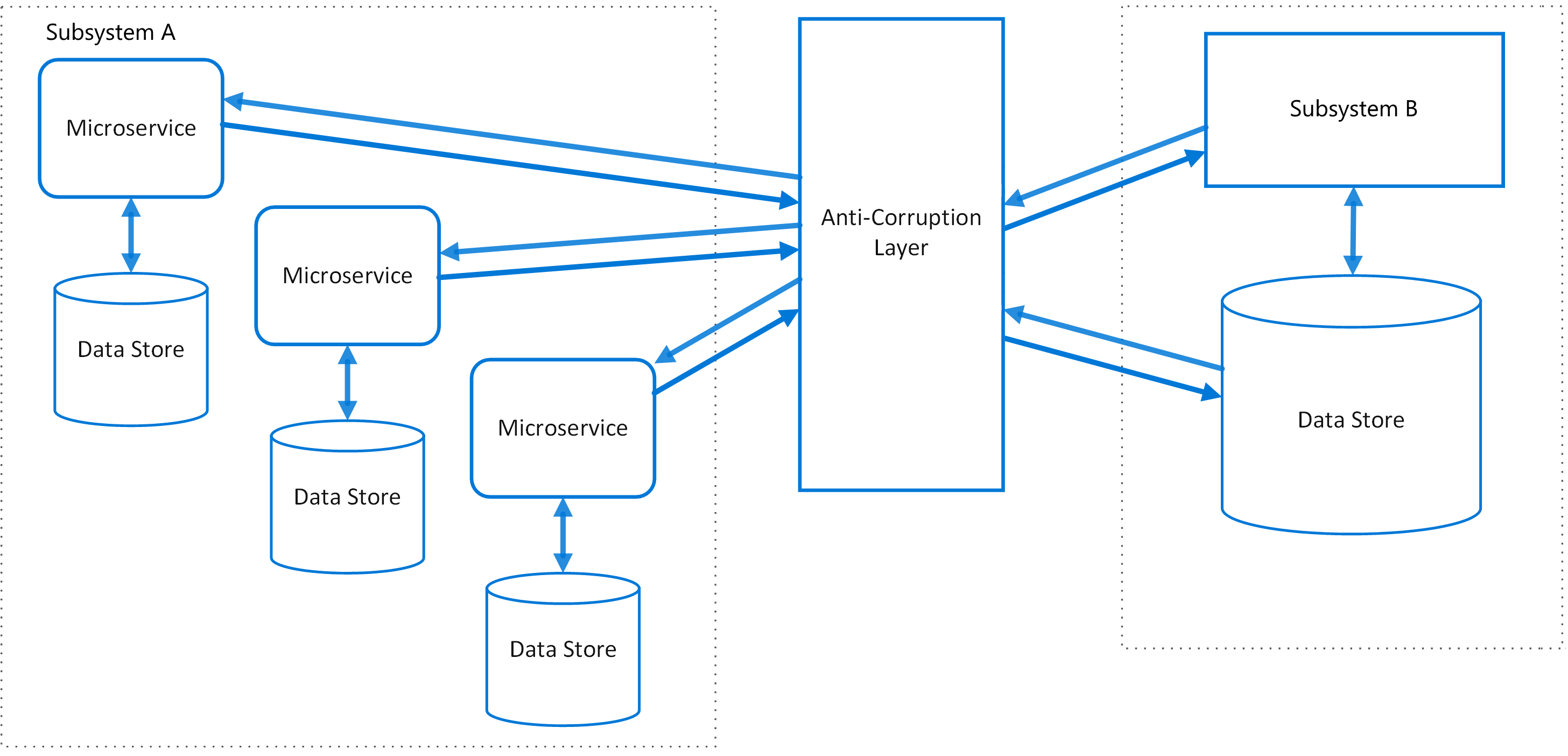
Calls from the anti-corruption layer to subsystem B conform to that subsystem's data model or methods. The anti-corruption layer contains all of the logic necessary to translate between the two systems. The layer can be implemented as a component within the application or as an independent service.
Read more on it here
Also see Strangler Fig pattern
Application Layer
- Logic that defines the actual features of our app. Use cases are the features of our app.
Application service
Any logic that performs operations on external resources (like using the Google Places API to get geolocation coordinates for an addresss) should belong in an Application Service.
- Application Services fetch the necessary entities, then pass them to domain services to run allow them to interact.
Also, see services
Class Invariant
See invariants for definition of invariants.
Class invariants are one of the strategies we can use to protect the size, shape, length or state of our domain objects. This method uses private constructors and static factory methods to ensure that the only way to create domain objects is through the static factory.
Exmaple from Khalil
interface EmailAddressProps {
value: string;
}
export class EmailAddress extends ValueObject<EmailAddressProps> {
get value () : string {
return this.props.value;
}
// Can't invoke with new from outside of class.
private constructor (props: EmailAddressProps) {
super(props);
}
// Only way to create an EmailAddress is through the static factory method
public static create (email: string): Result<EmailAddress> {
const guardResult = Guard.againstNullOrUndefined(email, 'email');
if (guardResult.isFailure() || !TextUtils.validateEmail(email)) {
return Result.fail<EmailAddress>()
} else {
return Result.ok<EmailAddress>(new EmailAddress({ value: email }))
}
}
}
Here is another example from Khalil Stemmler:
class UserValidator extends BaseValidator<IUser> {
constructor () {
super();
}
private validateName (name: string) : boolean {
// should be longer than 2 chars, less than 100
}
private validateEmail (email: string) : boolean {
// regex to check string
}
public validate (user: IUser) : boolean {
const isValidName = this.validateName(name);
const isValidEmail = this.validateEmail(email);
if (isValidName && isValidEmail) {
const user: User = User.create(name, email);
// continue
} else {
// error
}
}
}
In Domain-Driven Design, we aim to encapsulate the invariants/domain logic close to the actual models themselves
Class members
Class Members. An attribute or a method is a class member because they can ONLY be accessed through the class itself; therefore, they're members of the class.
See static members
Clean Architecture
How logic is organized in Clean Architecture:
- Presentation Logic: Logic that's concerned with how we present something to the user.
- Data Access / Adapter Logic: Logic concerned with how we enable access to infrastructure layer concern like caches, databases, front-ends, etc.
- Application Logic / Use Cases: Logic that defines the actual features of our app
- Domain Service logic: Core business that doesn't quite fit within the confines of a single entity.
- Validation logic: Logic that dictates what it means for a domain object to be valid.
- Core business logic / entity logic: Logic that belongs to a single entity.
We should write code that produce systems that are:
- Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
- Testable. The business rules can be tested without the UI, Database, Web Server, or any other external element.
- Independent of UI. The UI can change easily, without changing the rest of the system. A Web UI could be replaced with a console UI, for example, without changing the business rules.
- Independent of Database. You can swap out Oracle or SQL Server, for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
- Independent of any external agency. In fact your business rules simply don’t know anything at all about the outside world.
Concrete class
It's called a concrete class because:
- it can't be extended/subclassed by another class
- it has complete methods defined
We call the class a complete concrete class when it:
- In the case of implementing an interface, fully implements the properties and methods.
- In the case of extending an abstract class, implements the abstract methods.
Concrete classes can be instantiated and objects can be created from it. We cannot directly instantiate an abstract class or an interface.
type Color = 'blue' | 'red' | 'green'
enum HunterSkillLevel {
Novice,
Skilled,
Master
}
// Any class implementing this, be it an Animal, Person,
// Robot, etc.. needs to have these methods and properties.
interface IHunter {
skillLevel: HunterSkillLevel;
hunt (): void;
}
// Animal is an abstract class now. It can't be instantiated directly.
// But, it does allow for us to subclass it and create lots of different
// types of animals from it.
abstract class Animal {
protected color: Color;
constructor (color: Color) {
this.color = color;
}
// makeNoise should be implemented by any Animal subclass.
abstract makeNoise () : string;
}
// Wolf concrete class.
//
// The concrete class fully implements the requirements
// of the Animal abstract class by implementing the makeNoise method.
//
// It also fully implements the requirements of the IHunter
// interface by including the HunterSkillLevel and implementing the
// hunt method.
//
// We can instantiate this directly.
class Wolf extends Animal implements IHunter {
public skillLevel: HunterSkillLevel;
constructor (color: Color, skillLevel: HunterSkillLevel) {
super(color);
this.skillLevel = skillLevel;
}
hunt (): void {
// Get mean
}
makeNoise (): string {
return "Arooooooooo"
}
}
// Finally, we can create objects from our concrete Wolf class.
const meanWolf = new Wolf('blue', HunterSkillLevel.Master);
const babyWolf = new Wolf('red', HunterSkillLevel.Novice);
Consistency rules
Rules that an aggregate must meet on a transaction, and these are enforced inside of an consistency boundary. All these rules may be maintained at some point, but will need to be maintained during a transaction.
We can see this example from Eric Evan's Domain Language video:
Also see object instance diagram
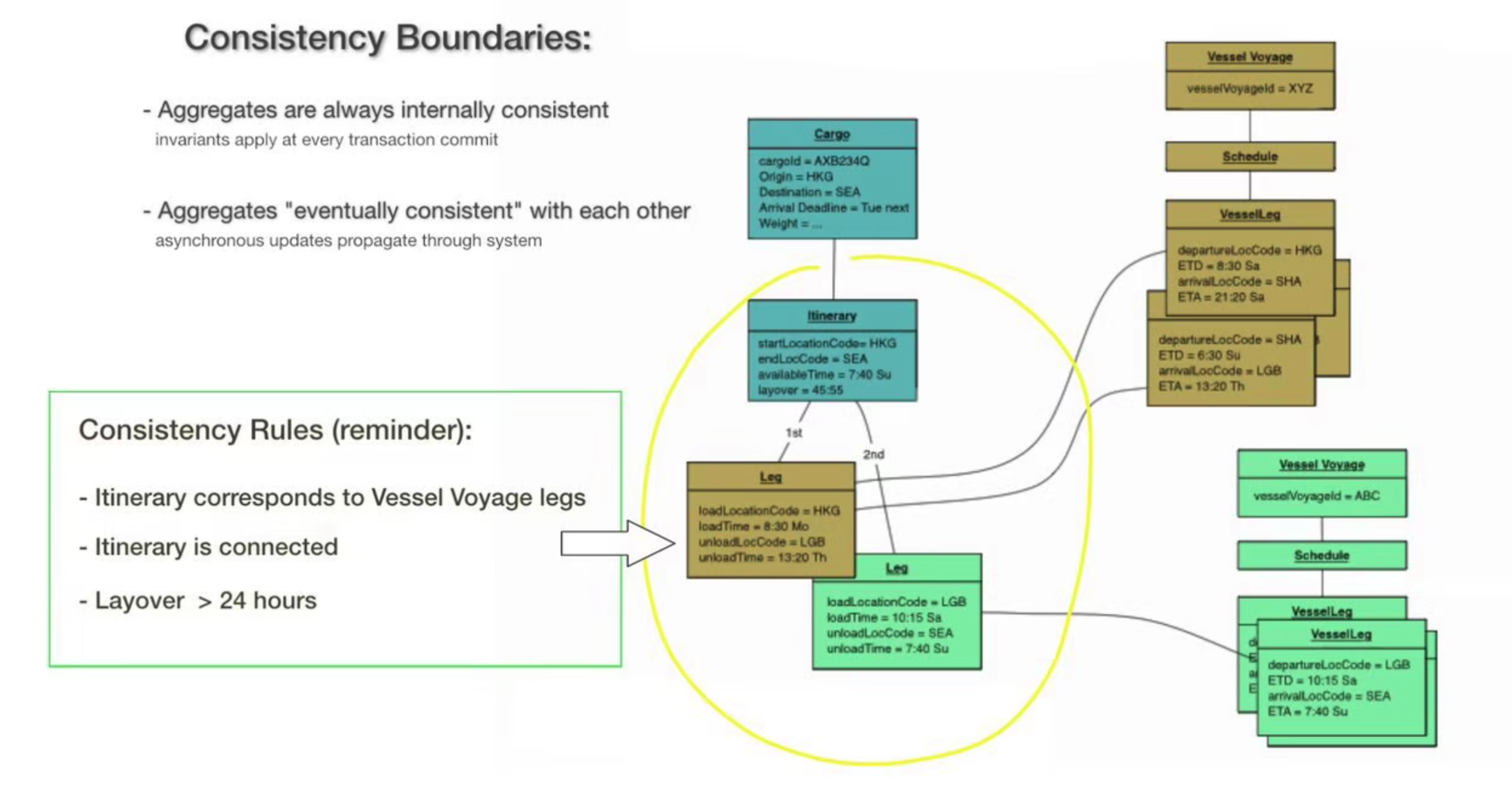
Notice consistency rules are enforced in side of the consistency boundary:
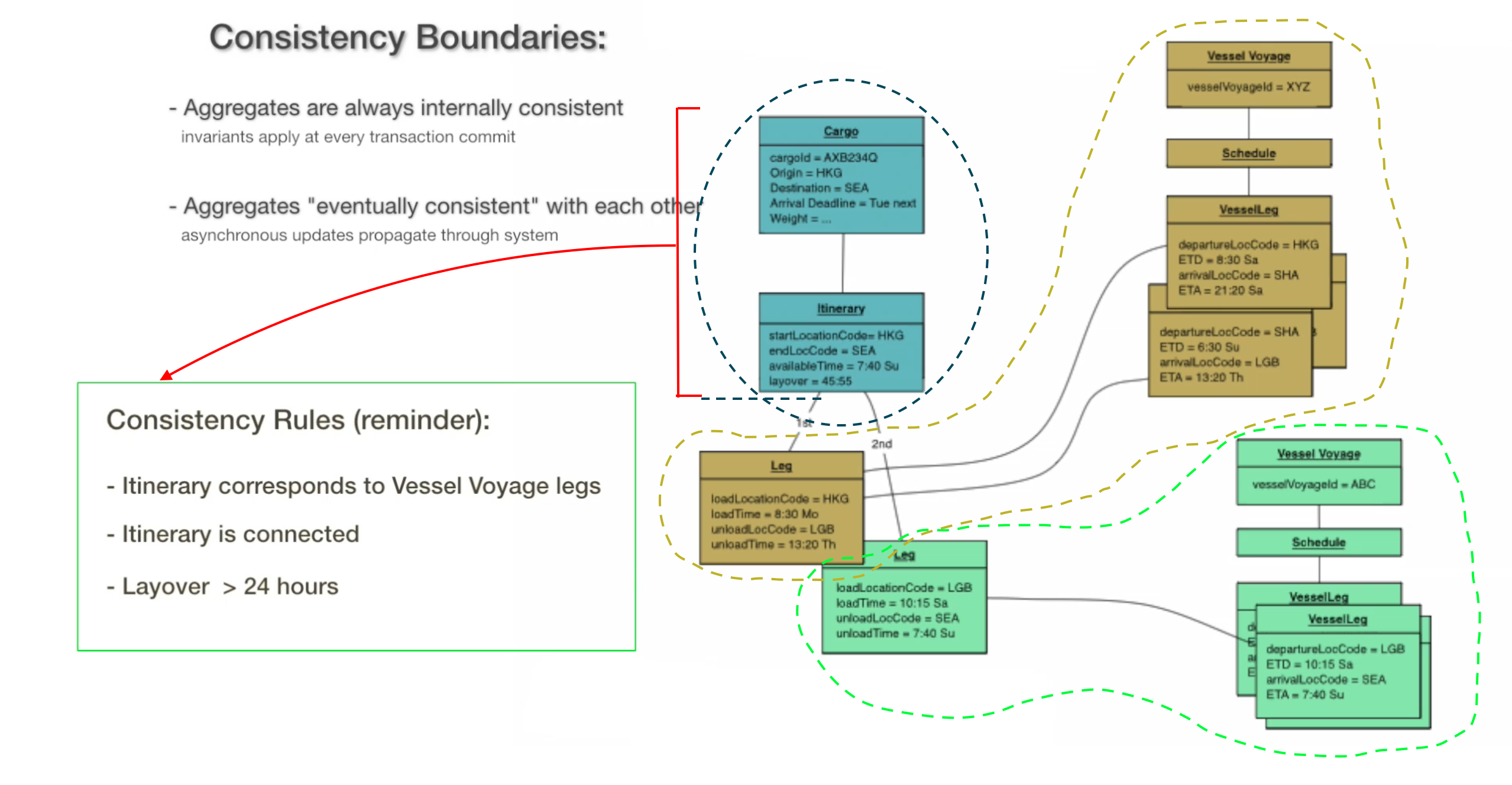
Consistency Boundaries
With aggregates, we draw explicit boundaries along particular explicit instances of those aggregates. These are modeled on object instance diagrams to see how changes made to a particular instance ripples through different objects.
Within boundaries, updates within these aggregates will always be handled transactionally, following consistency rules. Aggregates will always be internally consistent and invariants apply at every transaction commit.
For changes accross those boundaries, aggregates will be "eventually consistent" with each other and asynchronous updates propagate through the system.
An instance diagram broken down by three aggregates:
When using an object instance diagram for aggregate design, it helps us see how the boundaries would be better designed. For example, the previous image can be further looked at to realize if certain objects need to be consistent, in this case the Legs on the left side. We can then re-do the aggregates as such:
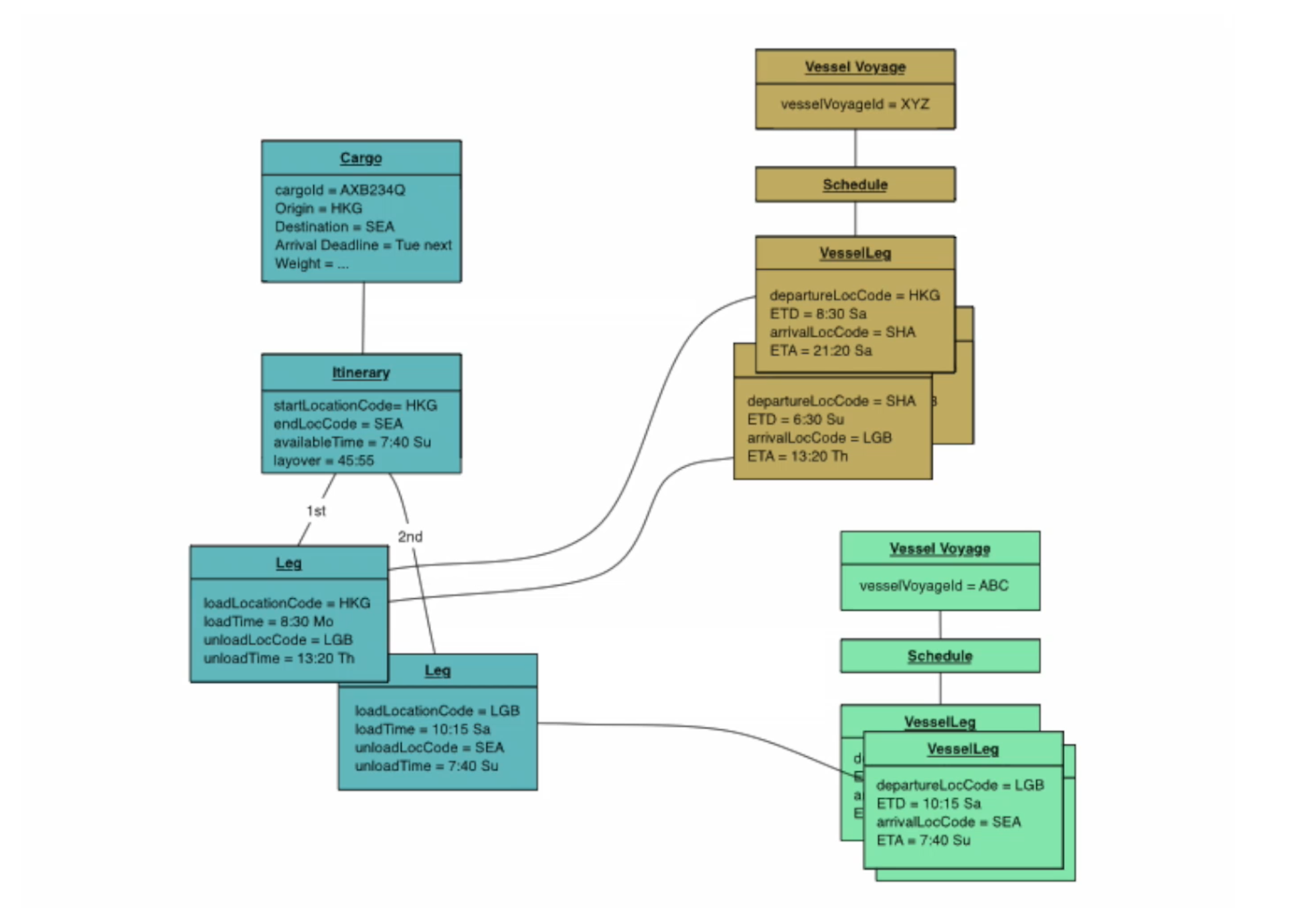
Now Itinerary and its legs are all in one aggregate since itinerary times need to be consistent with times on the legs. And any logic involving the relationship of different legs with each other can be straight forward and make the simplfying assumption that all the legs are from the same point in time. Also note the itinerary and vessel voyage doesn't need to be inolved.
Conway's law
Any organization that designs a system (defined more broadly here than just information systems) will inevitably produce a design whose structure is a copy of the organization's communication structure.
"Organizations that design systems, are constrained to produce designs that are copies of the communication structures of these organizations."
In simple terms: when we build software, we need to know the different groups/teams/roles it serves, and divide the app up into separate parts, similar to how those groups normally communicate in real life
See more here
CQS: Command Query Segregation
Command-Query Segregation (CQS) is an object-oriented design principle that statues a method can be either a COMMAND that performs an action or a QUERY that returns data to the caller, but never both.
In Command-Query Segregation, COMMANDS perform changes to the system but return no value, and QUERIES pull data out of the system, but produce no side effects.
In Domain-Driven Design, it makes sense to separate the READ models from the WRITE models. WRITEs usually take a little bit more time to finish executing because a WRITE to an aggregate requires the aggregate to be fully-constituted and contain everything within it's consistency boundary in order to enforce invariants.
Data Access / Adapter Logic
This layer contains logic concerned with how we enable access to infrastructure layer concern like caches, databases, front-ends, etc.
- This layer is all about defining the adapters to the outside world.
- Simplify usage for the inner layers by encapsulating the complexity of persisting an aggregate to a database by creating a Repository class to do that.
Common things done in this layer:
- RESTful APIs: Define a RESTful API with Express.js and create controllers to accept requests.
- Production middleware:Write Express.js controller middleware to protect your API from things like DDos and brute force login attempts.
- Database Access: Create repositories that contain methods that perform CRUD on a database. Use either an ORM like Sequelize and TypeORM or raw queries to do this.
- Billing Integrations: Create an adapter to a payment processor like Stripe or Paypal so that it can be used by inner layers.
Dependency Inversion Principal
The D in SOLID Design Principles.
A de-coupling technique where both high-level and low-level classes depend on the same abstraction, inverting the dependency relationship.
When large bodies of code are tightly coupled, they become ultimately unchangable and difficult to test. Well-designed software allows us to swap out dependencies that we're not currently interested in testing, with mocks.
- Abstractions should not depend on details. Details should depend on abstractions.
- High-level modules should not depend on low-level modules. Both should depend on abstractions
Example
If we have a Store that uses a Stripe API, the Store class will have the logic of calling the Stripe API within it. If we decide to change Stripe to Paypal Additionally, if we need to test our Store class, we need to make all of these Stripe API calls.
Instead, we should put an interface in the middle, maybe Payment Processor, that has a bunch of functions we want a payment processor to do like checkCard, makePayment that is just "an idea" of what we want it to do. And we can do a Stripe API implemenation of the payment processor. Additionally, we can also create a paypal API implementation of payment processor. Store calls payment_processor.checkCard, and not the actual detail of the dependency we are using (i.e. Stripe or Paypal), and instead use the interface that wraps those functionalities.
class Store {
constructor(user) {
this.stripe = new Stripe(user)
}
purchaseBike(quantity) {
this.stripe.makePayment(200 * quantity * 100)
}
purchaseHelmet(quantity) {
this.stripe.makePayment(15 * quantity * 100)
}
}
class Stripe {
constructor(user) {
this.user = user
}
makePayment(amountInCents) {
console.log(`${this.user} made payment of $${amountInCents / 100} with Stripe`)
}
}
// If we decide to switch to Paypal, notice Paypal doesn't have a user property, they take dollars instead of cents, and the makePayment function is different.
// Now we will need to change the Store with this implementation, and will need to change the constructor along with the purchaseBike and purchaseHelment methods
class Paypal {
makePayment(user, amountInDollars) {
console.log(`${user} made payment of $${amountInDollars / 100} with Paypal`)
}
}
Instead, we should put an interface (or intermediate API) that wraps around Stripe/Paypal that has exact same functions.
class Store {
constructor(paymentProcessor) {
this.paymentProcessor = paymentProcessor
}
purchaseBike(quantity) {
this.paymentProcessor.pay(200 * quantity * 100)
}
purchaseHelmet(quantity) {
this.paymentProcessor.pay(15 * quantity * 100)
}
}
class StripePaymentProcessor {
constructor(user) {
this.user = user
this.stripe = new Stripe(user)
}
pay(amountInDollars) {
this.stripe.makePayment(amountInDollars * 100)
}
}
// Stripe API
class Stripe {
constructor(user) {
this.user = user
}
makePayment(amountInCents) {
console.log(`${this.user} made payment of $${amountInCents / 100} with Stripe`)
}
}
class PaypalPaymentProcessor {
constructor(user) {
this.user = user
this.paypal = new Paypal()
}
pay(amountInDollars) {
this.paypal.makePayment(this.user, amountInDollars)
}
}
// Paypal API
class Paypal {
makePayment(user, amountInDollars) {
console.log(`${user} made payment of $${amountInDollars / 100} with Paypal`)
}
}
const store = new Store(new StripePaymentProcessor('John'))
store.purchaseBike(2)
// And if we implement Paypal, we need to just change the last 2 lines to:
const store = new Store(new PaypalPaymentProcessor('John'))
store.purchaseBike(2)
Uncle Bob's rules
- Don't refer to concrete classes. Refer to abstract interfaces instead. This puts a constraint on object creation and generally enforces the use of Abstract Factories.
- Don't derive from volatile concrete classes.
- Don't override concrete functions. These require source code dependencies
- Never mention the name of anything concrete.
Dependency Rule
That rule specifies that something declared in an outer circle must not be mentioned in the code by an inner circle.
This rule says that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in an inner circle. That includes, functions, classes. variables, or any other named software entity. — Uncle Bob
That means that code dependencies can only point inwards. We can use the Dependency Inversion Principle to declare in the inner layers abstractions that will be implemented (and potentially injected at runtime) in the outer layers. So inner and outer layers depend on abstractions instead of implementation details.
For example, Domain Layer code can't depend on Infrastructure Layer code, Infrastructure Layer Code can depend on Domain Layer code (because it goes inwards).
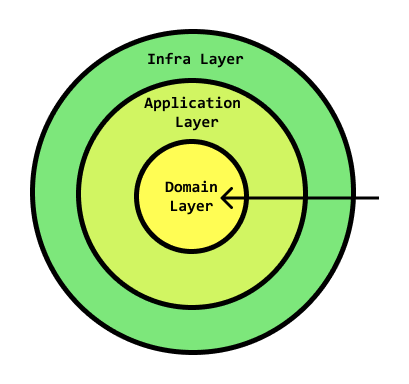
Domain
Domain is the subject our softwaer is about, or more abstracticaly a sphere of knowlede or avitivty.
Model is a system of abstractions representing selected aspects of a domain. Model is just concepts, system of abstractions.
Domain and Problem domain essentially mean the same thing. This is the actual problem our software will solve
Synonomous words the solution for the problem or artifact of the solution:
- Business logic
- Business rules
- Domain logic
- Domain knowledge
- Domain model
Business logic or domain classes exist in the two most inner layers of Onion Architecture
Domain Classes
Can be any of the items in the two most inner layers of the onion architecture. This includes:
- entity
- value objects
- domain events
- aggregates
- repositories
- factories
- domain services
Domain-Driven Design
Domain-Driven Design is an approach to software development that aims to match the mental model of the problem domain we're addressing.
Initially conceptualized by Eric Evans who wrote the bible of DDD (famously known as the Blue Book), DDD's primary technical benefits are that it enables you to write expressive, rich and encapsulated software that are testable, scalable and maintainable.
Goals:
- Discover the domain model by interacting with domain experts and agreeing upon a common set of terms to refer to processes, actors and any other phenomenon that occurs in the domain.
- Take those newly discovered terms and embed them in the code, creating a rich domain model that reflects the actual living, breathing business and it's rules.
- Protect that domain model from all the other technical intricacies involved in creating a web application.
Domain Event
Domain events can be used to notify other parts of the system when something happens. As the name suggests, domain events should mean something within the domain. For example, "a record was inserted into a table" is not a domain event. "A delivery was cancelled" is a domain event. Domain events are especially relevant in a microservices architecture. Because microservices are distributed and don't share data stores, domain events provide a way for microservices to coordinate with each other.
Domain events are simply objects that define some sort of event that occurs in the domain that domain experts care about.
Dispatched by aggregates which can be used to co-locate business logic in the appropriate subdomain.
Using the Observer pattern, we can use domain events to cross architectural boundaries (subdomains)
When essential properties are accessed or changed, it might make sense to create a Domain Event.
Always separate the creation from the dispatch of the domain event. WHen a domain event is created, it 's not dispatched right away. Your ORM is the single source of truth for a successful transaction
- A lot of ORMs have mechanisms built in to execute code after things get saved to the database.
Instead of adding more
if/elseblocks, we should instead use domain events. Here is an example:
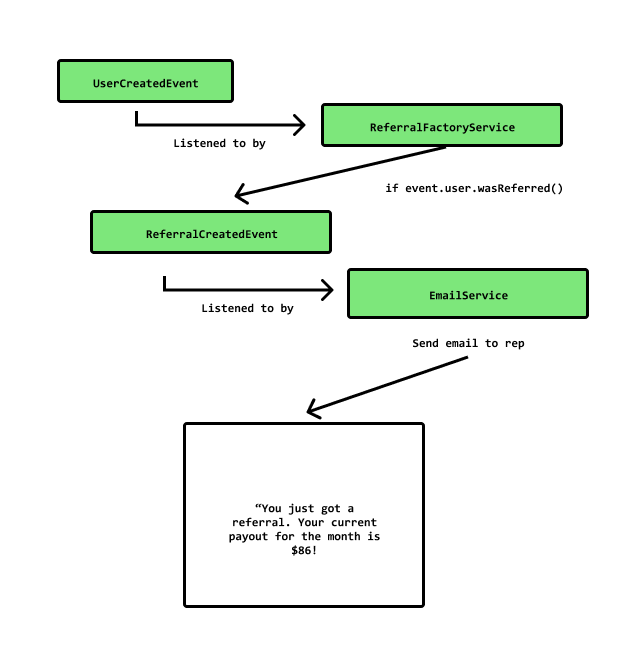
Using domain services (such as the ReferralFactoryService) and application services (such as the EmailService), Domain Events can be used to separate the concerns of the domain logic to be a executed from the subdomain it belongs.
Domain Service
Encapsulates business logic that doesn't naturally fit within a domain object, and are NOT typical CRUD operations – those would belong to a Repository. Any logic that doesn't quite belong to a single entity should remain in a Domain Service.
- Domain Services are most often executed by application layer Application Services / Use Cases.
- They are part of the Domain layer and adhere to the dependency rule.
- Thus, Domain Services aren't allowed to depend on infrastructure layer concerns like Repositories to get access to the domain entities that they interact with
- Application Services fetch the necessary entities, then pass them to domain services to run allow them to interact.
Domain services logic and interfaces belong in the domain layer and their concrete implementation in the infrastructure layer.
Also see services
Entity
Entities are domain objects that we care to uniquely identify (i.e. User, Account, Shipment, Comment, Posting). For example, in a banking application, customers and accounts would be entities.
Entities can be created, retrieved from persistence, archived, updated, and deleted. An Entity is compared by its unique identifier (UUID).
Any business logic in services that can be identified as the sole responsibility of an entity should be moved to that entity.
- Entities are the first place that we think of to put domain logic (if it makes sense)
- Enforce model invariants
- An entity has a unique identifier in the system, which can be used to look up or retrieve the entity. That doesn't mean the identifier is always exposed directly to users. It could be a GUID or a primary key in a database.
- An identity may span multiple bounded contexts, and may endure beyond the lifetime of the application. For example, bank account numbers or government-issued IDs are not tied to the lifetime of a particular application.
- The attributes of an entity may change over time. For example, a person's name or address might change, but they are still the same person.
- An entity can hold references to other entities.
Also see Value Objects and Aggregates
Infrastructure service
Also, see services
Invariant
Invariants are "constraints" that help protect rules on domain objects that may dictate size, shape, length or state.
Invariants are a form of ensuring data integrity of an object, meaning:
- the shape that the data is allowed to take,
- the methods that can be called and at which point
- the required parameters and preconditions to create this object
The difference between validation and invariant is that validation is the process of approving a given object state, while invariant enforcement happens before that state has even been reached. Meaning invariant enforcement is the responsibility of the domain entities(especially of the aggregate root) and an entity object should not be able to exist without being valid. Invariant rules are simply expressed as contracts, and exceptions or notifications are raised when they are violated.
There are several ways to protect invariants:
1. Wrapping primitives in domain-specific types.
Here is a way to encode business requirements and prevent illegal states by wrapping primitives in domain-specific types:
interface PostIdProps {
id: string;
}
export class PostId {
// Value is protected
private props: PostIdProps;
// There is only a getter, because it should never be able to change
get value (): string {
return this.props.id
}
}
interface PostTitleProps {
title: string;
}
export class PostTitle {
// Also protected
private props: PostTitleProps;
// Also only needs a getter
get value (): string {
return this.props.title;
}
}
Even though PostId and PostTitle might just be wrappers to a string value, it enforces state and prevents substitution of each other.
2. Monad Pattern to Strictly typing "null"s
Representing null or undefined with its own type, like Nothing.
See Monad Pattern
3. Class Invariants
See Class Invariant
4. Use public setters sparingly
Layered Architecture
A well constructed DDD model organizes a central domain layer at the core of our Layered Architecture and use a LOT of dependency inversion & injection in order to connect interface adapters to persistence, web and external technologies.
A large part of DDD is protecting the domain model by using a layered architecture. The layered architecture is also known as the Clean Architecture from Uncle Bob.
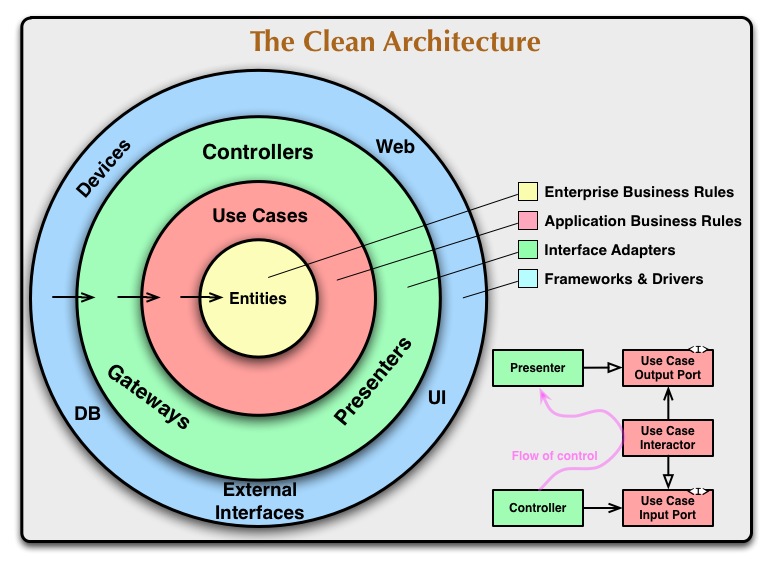
DDD follows a variation of the layered architecture and can be seen below using an Onion Model:
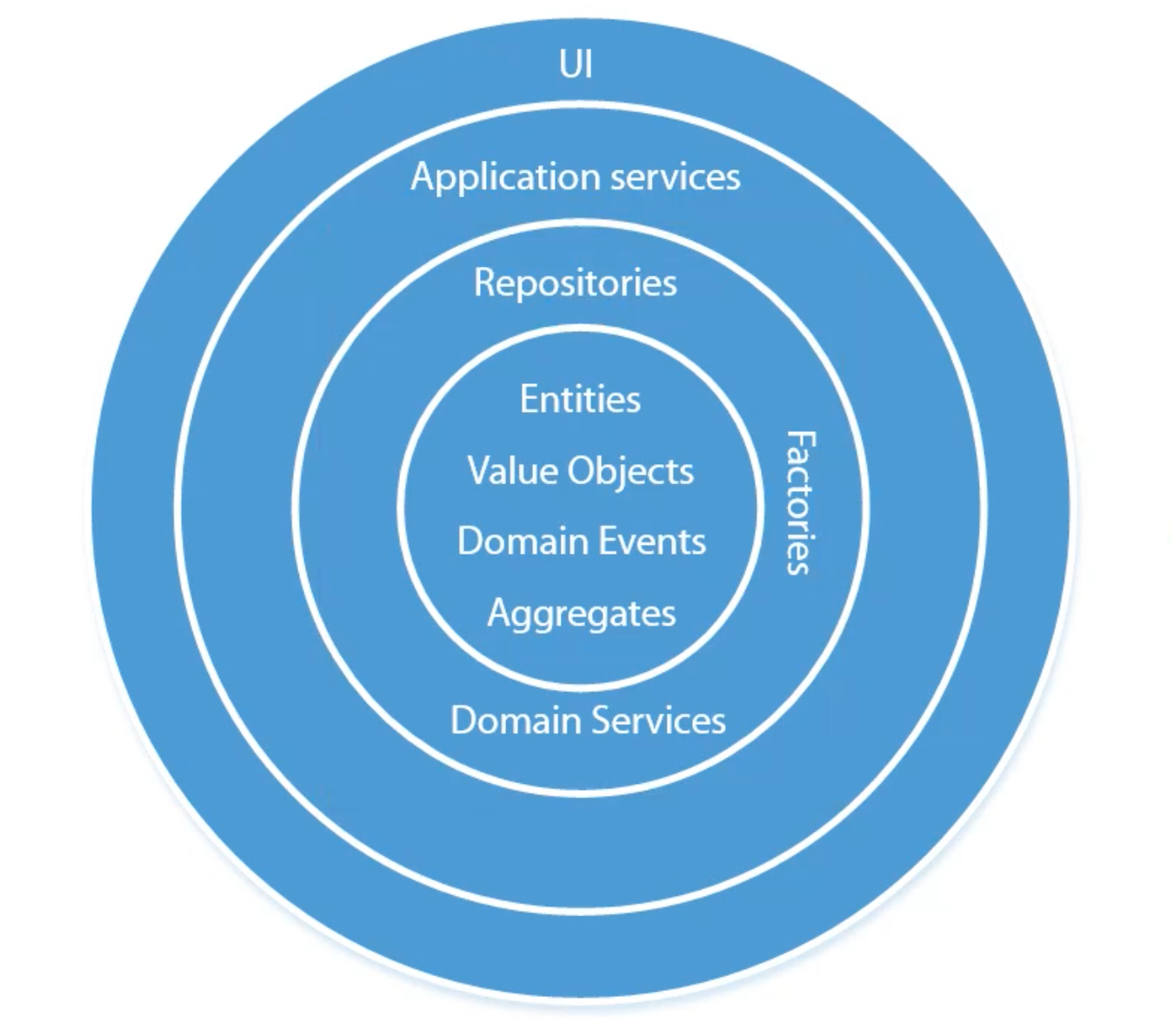
| Layer | Description | Includes | Concerns |
|---|---|---|---|
| Domain | Logic concerned with how we enable access to infrastructure layer concern like caches, databases, front-ends, etc. | Entities, Value Objects, Domain Events | validation logic |
| Application | Use Cases, Application Services (features of our App) | ||
| Data Access / Adapter Logic | Access to infrastructure and external APIs | ||
| Infrastructure | Controllers, Routes, databases, Caches, ORMs |
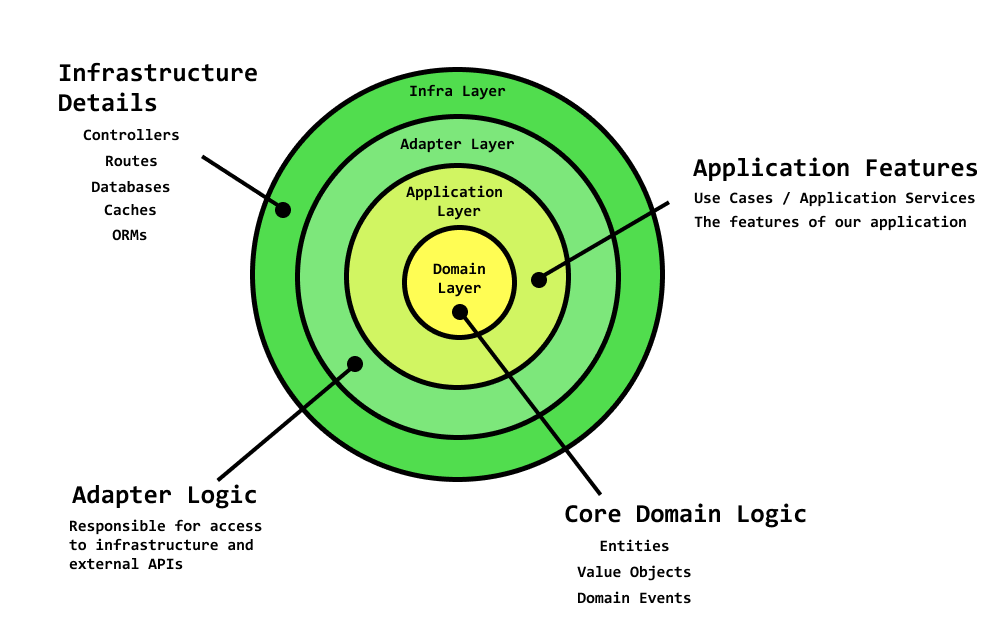
As stated by Uncle Bob, when designing our architecture we should aim for an architecture :
- independent of Frameworks
- testable
- independent of UI
- independent of Database
- independent of any external agency
Model
Model is a system of abstractions representing selected aspects of a domain. Model is just concepts, system of abstractions.
Models are central to DDD, but the word ‘model’ means many things, so we need to be specific. The sense of the word we apply in DDD is a basic and old one, not specifically tied to software: We simply say a model is a system of abstractions.
Characteristics of a model:
- focus only on relevant information
- formalize our thinking
- make assertions about the result (i.e. what will happen if an articifact is used in a certain way)
- i.e. For Mercator's model of the map of the world, the angle between any 2 points corersponds to a compass heading
- We shouldn't let the clarity or simplicity of the model
Things to watch out for:
- Don't try to do everything with one model.
- Don't worry about realism. Sometimes we undermine our model because we get overly focused on reality and say things like "does this model represent how the domain really works."
- We;re not looking for a realistic model, rather we're looking for a model we can use to solve a difficult problem
- Beware of perfectionism
What a model is: A model is a system of abstractions: A model is not an artificat, but a system of abstractions or set of concepts to reason about a domain Address subset of info about domain: A distillation of knowledge about that domain. It excludes information that is not relevant to the problem at hand. It addresses a subset of information about the domain. Specialized: It isn't general, it is Specialized. We're not trying to find a model that will solve our problems and represent a domain in every context. Models are artifical: Models evolve. We are not looking for the ultimate or perfect model, or true model that represent reality. We are looking for practical models that comes within our reach in the timeframe of our software project that helps us deal with the trickiest part of that software.
Userfulness of models
- model is not about realism
- is this model useful?
- choose a model that's suited to the pupose at hand
- there will be more than one model in use
Monad Pattern
A functional design pattern used to represent types that may or may not exist.
type Nothing = null | undefined | ''
This allows us to create optional types using unions:
type SomeString = string
type OptionalString = SomeString | Nothing
type SomeNumber = number
type OptionalNumber = SomeNumber | Nothing
Or we can make it generic in order to strictly represent any type that may or may not have a value.
type Option<T> = T | Nothing
type OptionalString = Option<string>
type OptionalNumber = Option<number>
When we model nothingness as a type in our domain instead of just passing null, it forces any client code that relies on it to accomodate the possibility of nothingness.
Object instance diagram
A good way of showing the state of a particular objects within a system at a particular point in time.
In this digram, each object is represented as a separate box rather than the boxes reprefesnting abstraction of the class. This is much more useful when we are dealing with aggregates and consistency issues because these are instance level concepts.pts. The individuals instances of the given class are going to change at different times.
We often use object instance diagrams during aggregate design when looking at consistency rules and defining consistency boundaries.
We can use an object instance diagram to see how changes made to a particular instance ripples through to different objects within the instance diagram.
Example diagram:
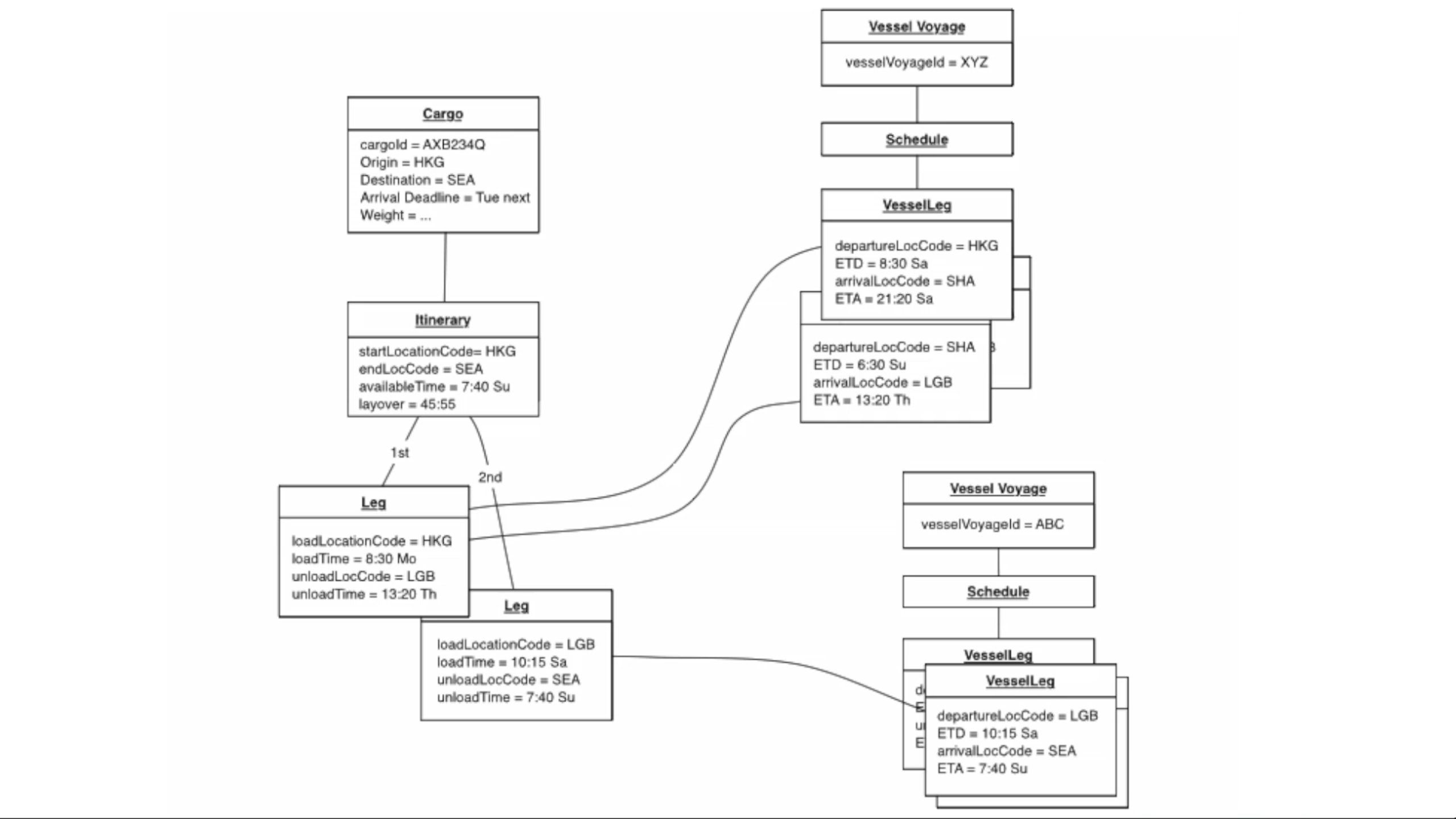
Example diagram with consistency boundaries:
Observer pattern
- We can use the observer pattern for domain events to cross architectural boundaries (subdomains)
Primitive Obsession
A Code Smell that Hurts People the Most
Primitive fields are basic built-in building blocks of a language (i.e. int, string, Number, Object).
Primitive Obsession is when the code relies too much on primitives. It means that a primitive value controls the logic in a class and this value is not type safe. Therefore, primitive obsession is when you have a bad practice of using primitive types to represent an object in a domain.
Private constructor
Changing the scope of a constructor to private removes our ability to use the new keyword, and constructor can only be used within the class itself for instantiating a class.
This is most commonly done to enforce validation object against a domain object by the use of static factory methods.
Repository
A repository is a facade for retrieving and querying aggregates from the database, used to avoid tight coupling between this querying/saving logic and the technical implementation.
Repository interfaces belong in the domain layer and their concrete implementation in the infrastructure layer.
It's recommended that you define and place the repository interfaces in the domain model layer so the application layer, such as your Web API microservice, doesn't depend directly on the infrastructure layer where you've implemented the actual repository classes. By doing this and using Dependency Injection in the controllers of your Web API, you can implement mock repositories that return fake data instead of data from the database. This decoupled approach allows you to create and run unit tests that focus the logic of your application without requiring connectivity to the database.
See more here
Services
In DDD terminology, a service is an object that implements some logic without holding any state. Evans distinguishes between domain services, which encapsulate domain logic, and application services, which provide technical functionality, such as user authentication or sending an SMS message. Domain services are often used to model behavior that spans multiple entities.
The term service is overloaded in software development. The definition here is not directly related to microservices.
Services come in 3 flavors: Domain Services, Application Services, and Infrastructure Services.
- Domain Services : Encapsulates business logic that doesn't naturally fit within a domain object, and are NOT typical CRUD operations – those would belong to a Repository.
- Application Services : Used by external consumers to talk to your system (think Web Services). If consumers need access to CRUD operations, they would be exposed here.
- Infrastructure Services : Used to abstract technical concerns (e.g. MSMQ, email provider, etc).
Keeping Domain Services along with your Domain Objects is sensible – they are all focused on domain logic. And you can inject Repositories into your Services.
Application Services will typically use both Domain Services and Repositories to deal with external requests.
Static factory
The best way to enforce validation logic against a domain object is to keep the constructor private and use a static factory method to enforce the constraints.
Also see Private Constructor
Static members
When we use the static keyword on properties we define on a class, they belong to the class itself and not an instance of the class.
Also see class members
When do you use static properties:
Will this property ever need to be used by another class, without first needing to create an object of it? In other words, should I need to call it on an object created by this class or not? If yes, then continue normally.
If no, then you might want to make a static member.
Scenarios where it makes sense:
- to check a business rule or constraint from another class
- to implement a
factory methodto encapsulate the complexity required in order to create an instance of the class - to use an
abstract factoryin order to create a specific type of instance of the class - when the property shouldn't ever change
Scenarios where it sounds like it makes sense but leads to an anemic model:
- to perform validation logic on attributes for that class (use Value Objects instead)
Strangler Fig pattern
Incrementally migrate a legacy system by gradually replacing specific pieces of functionality with new applications and services. As features from the legacy system are replaced, the new system eventually replaces all of the old system's features, strangling the old system and allowing you to decommission it.
Incrementally replace specific pieces of functionality with new applications and services. Create a façade that intercepts requests going to the backend legacy system. The façade routes these requests either to the legacy application or the new services. Existing features can be migrated to the new system gradually, and consumers can continue using the same interface, unaware that any migration has taken place.
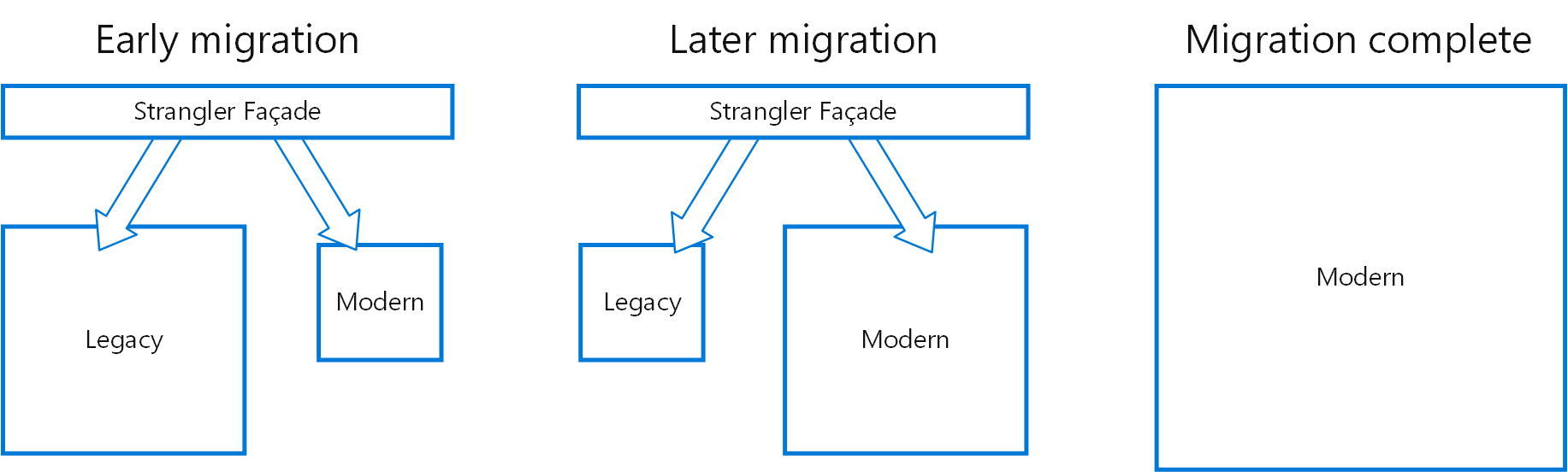
Use this pattern when gradually migrating a back-end application to a new architecture.
This pattern may not be suitable:
When requests to the back-end system cannot be intercepted. For smaller systems where the complexity of wholesale replacement is low.
Also see Anti-corruption layer
Strategic DDD
DDD has two distinct phases, strategic and tactical.
In strategic DDD, you are defining the large-scale structure of the system. Strategic DDD helps to ensure that your architecture remains focused on business capabilities.
During the strategic phase of DDD, you are mapping out the business domain and defining bounded contexts for your domain models.
Strategic patterns
In DDD, strategic patterns are large-grained patterns used to distill the domain knowledge and act as the global strategy to guide the implementation:
Subdomain
A subdomain is a logical separation of the entire problem domain. Use cases belong to a particular subdomain.
Conway's law can help us in deciding out subdomains, which use case belongs in which subdomain, and how do we make it easier to change use cases in the future.
Tactical DDD
DDD has two distinct phases, strategic and tactical.
Tactical DDD provides a set of design patterns that you can use to create the domain model. These patterns include entities, aggregates, and domain services. These tactical patterns will help you to design microservices that are both loosely coupled and cohesive.
- Tactical DDD is when you define your domain models with more precision.
- The tactical patterns are applied within a single bounded context.
As a general principle, a microservice should be no smaller than an aggregate, and no larger than a bounded context.

Test Coverage
It's important to keep a balance between test-coverage and the effort you put. 100% coverage of the entire codebase is not realistic and as valuable, as effort is linear. But, we should do 100% coverage for the domain logic.
We should do 100% or close to 100% test-coverage in the domain layer for entities, value objects, domain events and aggregates. You can also do high coverage for use cases and repositories.
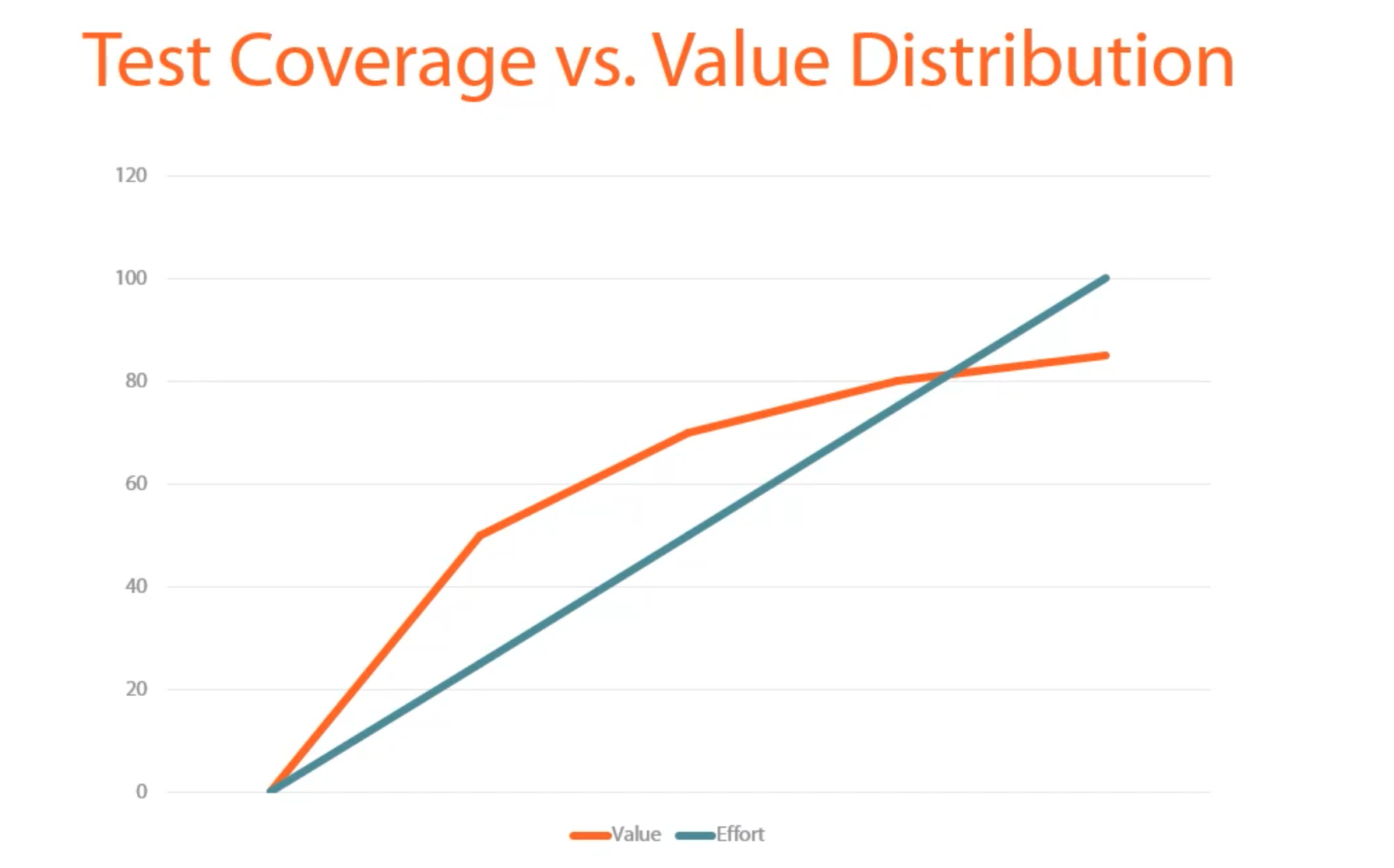
By separating concerns like database or email-service, it makes it easier to write test-coverage on the domain.
Other parts of the code (repositories, factories, application services) should have integation tests rather than unit tests.
Transactional boundary
This is referred to in the context of an aggregate. Each aggregate forms a transactional consistency boundary.
This means that within a single Aggregate, all composed parts must be consistent, according to business rules, when the controlling transaction is committed to the database.
This doesn't necessarily mean that you are not supposed to compose other elements within an Aggregate that don't need to be consistent after a transaction. After all, an Aggregate also models a conceptual whole.
The reasons for the transactional boundary are business motivated, because it is the business that determines what a valid state of the cluster should be at any given time. In other words, if the Aggregate was not stored in a whole and valid state, the business operation that was performed would be considered incorrect according to business rules.
Aggregate design guidelines:
- Modify and commit only one Aggregate instance in one transaction
- Protect business invariants inside Aggregate boundaries
- Design small Aggregates- Reference other Aggregates by identity only
- Update other Aggregate using eventual consistency
see also aggregates
Ubiquitous Language
A common language used to describe the domain model that is determined by speaking with domain experts. This language allows all parties, developers, stakeholders, domain experts, to connect the software implementation to what actually occurs in the real world.
This can only be determined by speaking with domain experts.
Ubiquitous Language is modeled within a Limited context, where the terms and concepts of the business domain are identified, and there should be no ambiguity.
Ubiquitous Language is the term that Eric Evans uses in “Domain-Driven Design – Tackling Complexity in the Heart of Software” in order to build a language shared by the team, developers, domain experts, and other participants.
Domain experts should object to terms or structures that are awkward or inadequate to convey domain understanding; developers should watch for ambiguity or inconsistency that will trip up design. — Eric Evans
Characteristics of the Ubiquitous Language
- Ubiquitous Language must be expressed in the Domain Model.
- Ubiquitous Language unites the people of the project team.
- Ubiquitous Language eliminates inaccuracies and contradictions from domain experts.
- Ubiquitous Language is not a business language imposed by domain experts.
- Ubiquitous Language is not a language used in industries.
- Ubiquitous Language evolves over time, it is not defined entirely in a single meeting.
- Concepts that are not part of the Ubiquitous Language should be rejected.
Use Case
- Defined in the application layer
- Use Cases are application specific
- Use Cases are either COMMANDS or QUERIES if we're following the Command-Query Segregation principle.
- Use Cases are synonomous to features, and encapsulate the business logic involved in executing the features within our app(s)
How to identify use cases
Use a use Use Case Diagram
This can be free-form drawings or something like the below image.
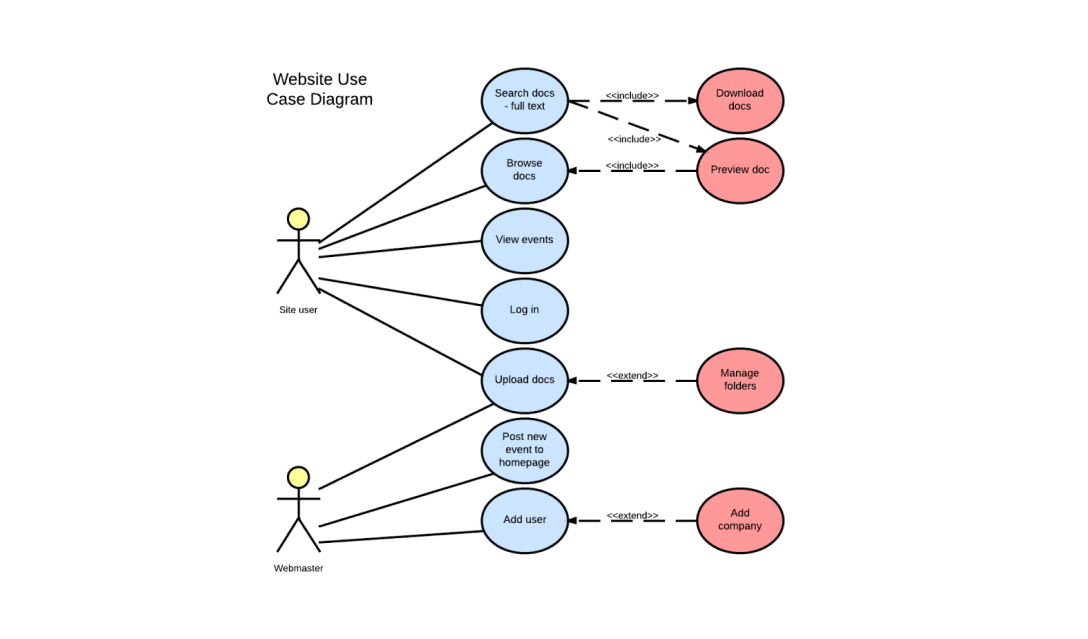
Key is:
- Determine who the
actors(or users) of the system are (who is executing the use cases) - Use cases are either comannds or queries
- Use cases are determined through conversations
UUID
- We want the Domain Layer code to be able create Domain Objects without having to rely on a round-trip to the database.
- This leads to faster unit test cases as well
- This separates concerns between creating objects and persisting objects.
- Domain events can be used differently to allow other subdomains and bounded contexts to react to changes in our system
Migrating existing DB
- Re-create a new DB with same tables but different primary key data types
Validation Logic
- Validation logic is another domain layer concern, not an infrastructure one.
- Logic that dictates what it means for a domain object to be valid.
Value Objects
An object that represents a descriptive aspect of the domain with no conceptual identity is called a Value Object. Value Objects are instantiated to represent elements of the design that we care about only for what they are, not who or which they are. — Eric Evans
- Value objects are attributes of entities and they have no identity of their own.
- The responsibility of value objects is to validate data.
- It is defined only by the values of its attributes.
- Value objects are also immutable.
- To update a value object, you always create a new instance to replace the old one.
- Value objects can have methods that encapsulate domain logic, but those methods should have no side-effects on the object's state.
- Typical examples of value objects include colors, dates and times, and currency values.
From Stemmler:
// A valid (yet not very efficient) way to compare Value Objects
const khalilName = {firstName: 'Khalil', lastName: 'Stemmler'}
const nick = {firstName: 'Nick', lastName: 'Cave'}
JSON.stringify(khalil) === JSON.stringify(nick) // false
Entity vs. Value objects:
- Entities are compared by their unique identifier and Value Objects are compared by their structural equality. Structural equality means that two objects have the same content. This is different from referential equality / identity which means that the two objects are the same.
- An entity is different from a Value Object primarily due to the fact that an Entity has an identity while a Value Object does not.
- Another distinction between the two notions is the lifespan of their instances. Entities live in continuum, so to speak. They have a history (even if we don’t store it) of what happened to them and how they changed during their lifetime. Value objects, at the same time, have a zero lifespan. We create and destroy them with ease.
- A guideline that flows from this distinction is that value objects cannot live by their own, they should always belong to one or several entities.
- Another corollary here is that we don’t store value objects separately. The only way for us to persist a value object is to attach it to an entity.
- Value objects should be immutable in a sense that if we need to change such an object, we construct a new instance based on the existing object rather than changing it. On the contrary, entities are almost always mutable.
- By mutating an instance of a value object, you assume it has its own life cycle. And that assumption, in turn, leads to a conclusion that the value object has its own inherent identity, which contradicts the definition of that DDD notion.
- That leads us to the following rule of thumb: if you can’t make a value object immutable, then it is not a value object.
Recognizing value objects in your model
- if you can safely replace an instance of a class with another one which has the same set of attributes, that’s a good sign this concept is a value object.
- A simpler version of that technique is to compare a value object to an integer. Do you really care if the integer 5 is the same 5 that you used in another method? Definitely not, all fives in your application are the same regardless of how they were instantiated. That makes an integer essentially a value object. Now, ask yourself, is this notion in your domain looks like integer? If the answer is yes, then it’s a value object.
Storing value objects in the Database
Example:
// Entity
public class Person
{
public int Id { get; set; }
public string Name { get; set; }
public Address Address { get; set; }
}
// Value Object
public class Address
{
public string City { get; set; }
public string ZipCode { get; set; }
}
The best solution to store this in the DB is to inline the fields from the Address into the Person table, like this:

Storing Person and Address in separate tables would cause Address to have an identifier which violates definition of value object. Furthermore, doing this we can potentially detach value objects from entities in case we delete a Person from the DB.
Don’t introduce separate tables for value objects, just inline them into the parent entity’s table.
Prefer value objects over entities
When it comes to working with entities and value objects, an important guideline comes into play: always prefer value objects over entities. Value objects are immutable and more lightweight than entities. Because of that, they are extremely easy to work with. Ideally, you should always put most of the business logic into value objects. Entities in this situation would act as wrappers upon them and represent more high-level functionality.
See also Aggregates
YAGNI
'You aren't gonna need it'
A design principle from Extreme Programming (XP) that states that a programmer shouldn't add any functionality until it's actually necessary.
Ron Jeffries, one of the founders of XP wrote that programmers should "always implement things when you actually need them, never when you forsee that you need them" and "do the simplest possible thing that will work".
- This can help you iterate really quickly.
- It helps prevent design fatigue or fear of a large all-encompassing up-front design.
YAGNI is meant to be combined with continuous refactoring, automated unit testing and continuous integration.
Failure to refactor code early could require huge amounts of technical debt and rework.
Therefore, in order to do YAGNI well, developers first need to know how to:
- write code that's testable
- run automated tests
Notes for Implementation
Rule: Model True Invariants in Consistency Boundaries
The universe is built up into an aggregate of permanent objects connected by causal relations that are independent of the subject and are placed in objective space and time. –Jean Piaget
When trying to discover the Aggregates in a Bounded Context (2), we must understand the model’s true invariants. Only with that knowledge can we determine which objects should be clustered into a given Aggregate.
Discovering Aggregates
When trying to discover the Aggregates in a Bounded Context (2), we must understand the model’s true invariants. Only with that knowledge can we determine which objects should be clustered into a given Aggregate.
An invariant is a business rule that must always be consistent. There are different kinds of consistency. One is transactional consistency, which is considered immediate and atomic. There is also eventual consistency. When discussing invariants, we are referring to transactional consistency. We might have the invariant
c = a + b
Therefore, when a is 2 and b is 3, c must be 5. According to that rule and conditions, if c is anything but 5, a system invariant is violated. To ensure that c is consistent, we design a boundary around these specific attributes of the model:
type AggregateType1 {
a: number
b: number
c: number
function1()
function2()
...
}
The consistency boundary logically asserts that everything inside adheres to a specific set of business invariant rules no matter what operations are performed. The consistency of everything outside this boundary is irrelevant to the Aggregate. Thus, Aggregate is synonymous with transactional consistency boundary. (In this limited example, AggregateType1 has three attributes of type number, but any given Aggregate could hold attributes of various types.)
When employing a typical persistence mechanism, we use a single transaction2 to manage consistency. When the transaction commits, everything inside one boundary must be consistent. A properly designed Aggregate is one that can be modified in any way required by the business with its invariants completely consistent within a single transaction. And a properly designed Bounded Context modifies only one Aggregate instance per transaction in all cases. What is more, we cannot correctly reason on Aggregate design without applying transactional analysis.
Limiting modification to one Aggregate instance per transaction may sound overly strict. However, it is a rule of thumb and should be the goal in most cases. It addresses the very reason to use Aggregates.
The fact that Aggregates must be designed with a consistency focus implies that the user interface should concentrate each request to execute a single command on just one Aggregate instance. If user requests try to accomplish too much, the application will be forced to modify multiple instances at once.
Therefore, Aggregates are chiefly about consistency boundaries and not driven by a desire to design object graphs. Some real-world invariants will be more complex than this. Even so, typically invariants will be less demanding on our modeling efforts, making it possible to design small Aggregates.