Lambda
Lambda Service Under the Hood
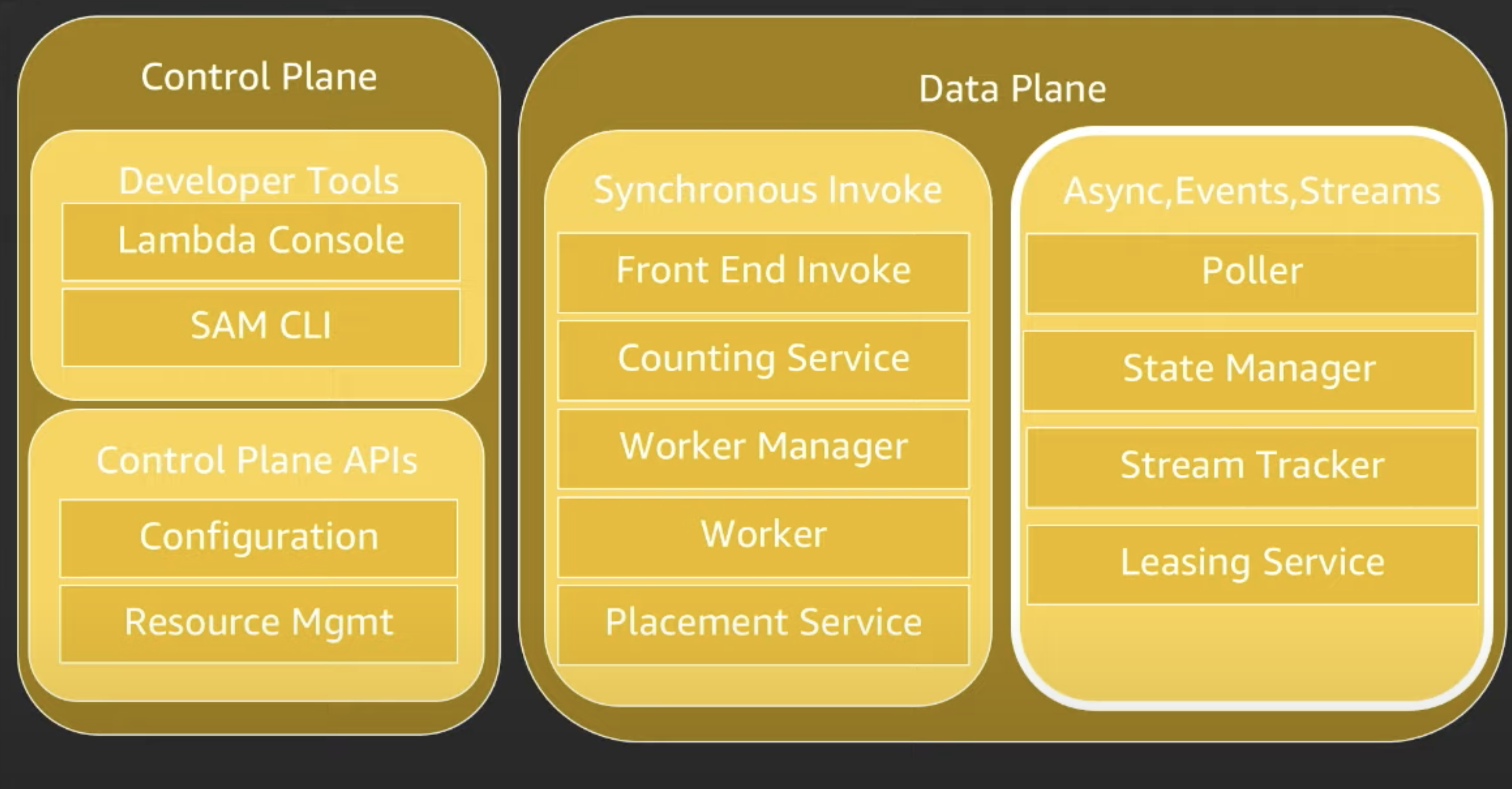
Lambda service is split into:
- Control Plane - where developers work with lambda, upload and configure your code in prep for execution
- Data Plane - where customers interact with lambda, what triggers code to execute
Synchronous Invoke
"Cold Start"
Synchronous First Time Invoke or Scale Up is commonly called a "Cold Start".
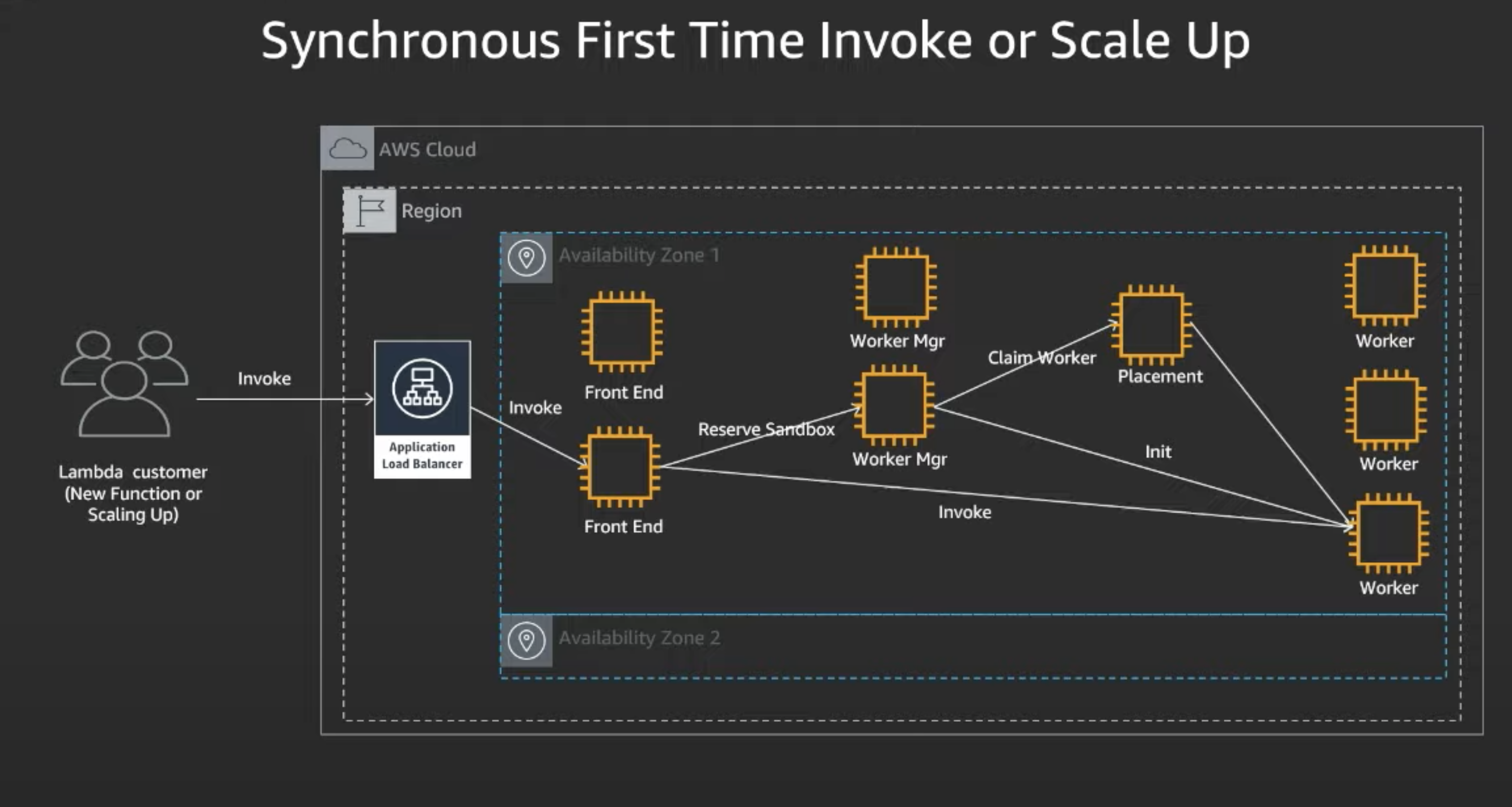
- Lambda customer calls "invoke",which hits Application Load Balancer that routes to the Front End.
- Front End authenticates caller and checks if it has permissions, then checks function meta-data and confirm per-function concurrency hasn't been exceeded
- Front End then routes to Worker Mgr, whose responsibility is to track warm sandboxes that are ready for invocation. If it is afirst time invocation or scale-up, there isn't a reserved sandbox available.
- Worker manager needs to communicate with the placement service, whose responsibility is to find the best location on a given host to place that workload.
- Placement provisions that sandbox and returns it to the worker manager, and the worker manager then calls "init" which initializes the function for invocation and returns to front-end -Front-end then can call "invoke"
"Warm Start":
Schronous Repeat Invoke is commonly called a "Warm Start". On a repeat, a warm start, and vast majority of inovations land here.
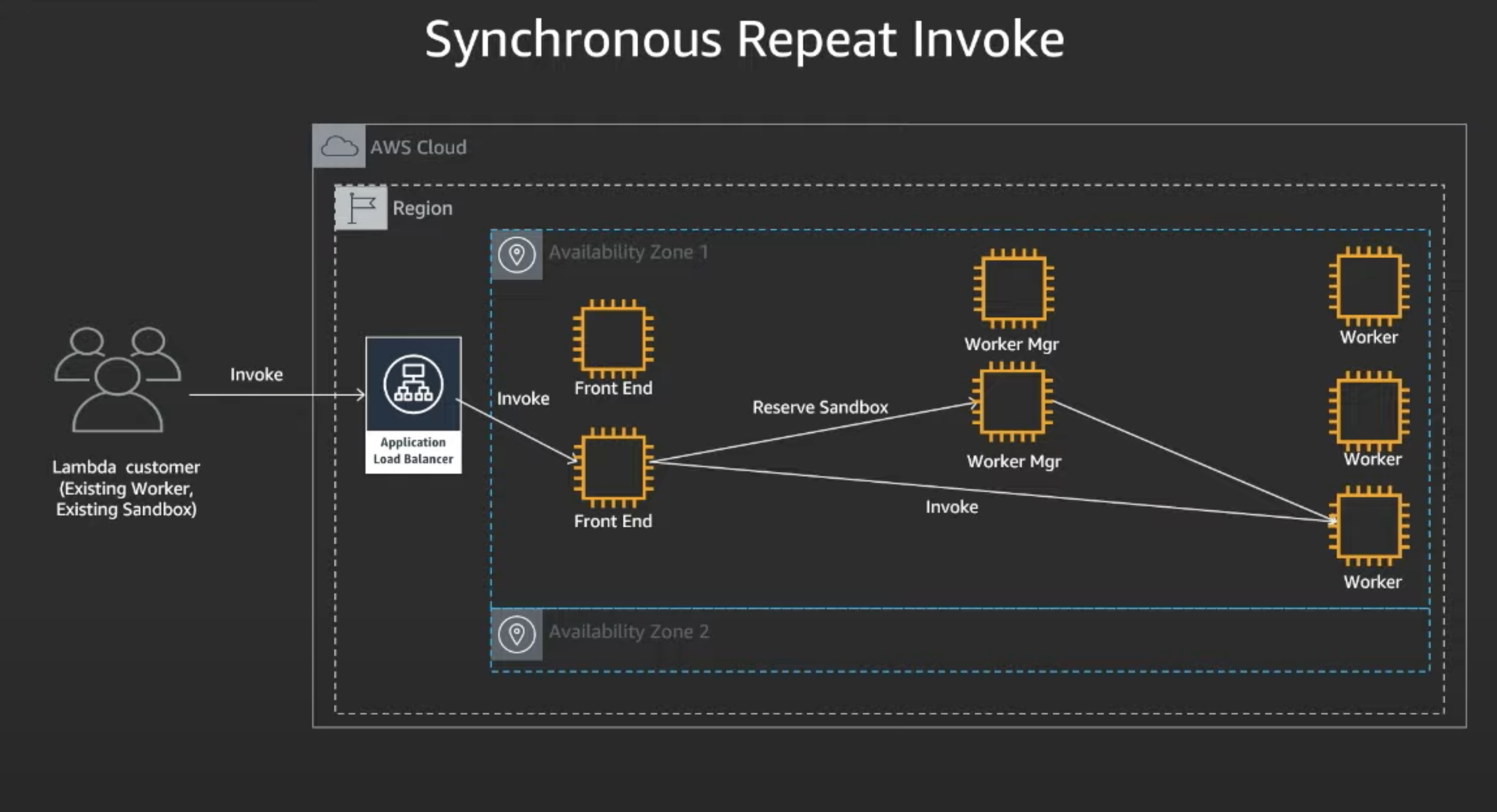
- Similar flow as "Cold Start" -> Customer calls invoke, hits load balancer, and goes to front-end
- Now at the worker manager, it knows there is a readily available sandbox worker available, and returns that to the front-end, making it much faster
Async Invoke
Poller
- Responsible for consuming events and ensuring they are processed.
- For event sources, it consumes events from queues, either customer owned (like SQS) or lambda owned like async. Retrieves function event destination config data, triggers sync invoke with payload, manages retries in case of failure, checkpoints in a heartbeat, delivers the completion data for function data to an event destination.
- For streaming sources, it subscribes to shards, monitors changes to function name, meta data or batch size and updates local state, invokes the lambda function as soon as any data is received, supports batching rules invoking lambda function for a batch size of data or batch time, if it throttles, it backs off and retries, checkpoints in a heartbeat, updates the streaming source with reason code when it receives an unrecoverable exception, and drops its assignment when the streaming source is disabled or deleted.
State Manager or Stream Tracker
- Responsible for handling scaling by managing pollers,and event or stream source resources.
- For event sources, it is the state manager. It creates new static queues as it scales up with load for large per function concurrency. It creates or updates the desired number of polling assignments in the leasing service. Monitors creating updating and transioning states, driving to the desired state to the event source. Creates dwell time or assignment level metrics used as an indicator of system-wide performance.
- For streaming sources, it is the stream tracker. It exposes an API to manage streaming sources. Cause list shards and creates leases with the leasing service for each of the shards. Check periodically for function updates and other streaming source updates which require changes on leases, scans for streaming sources checking for any streaming source when a lease as not been created, exposes an API to sync a shard when a poller has reached shard end and disables the streaming source when all the shards have reached shard end"
Leasing Service
- Responsible for assigning pollers to work on a specific event or streaming source.
- For event source, it manages poller assignmnets as specified by the state manager. It maps pollers to queues, decides the number of pollers per queue to process events. Handles acquiring and releasing poller assignments and checks periodically assignment health and makes unhealthy assignmnets available to new pollers.
- For streaming sources, it scans and provides assignments to pollers, exposes and api which the stream tracker uses to manage giving and releasing assignments on pollers, and acquires the shards after their parents have been executed up to shard end.
Async Event invoke
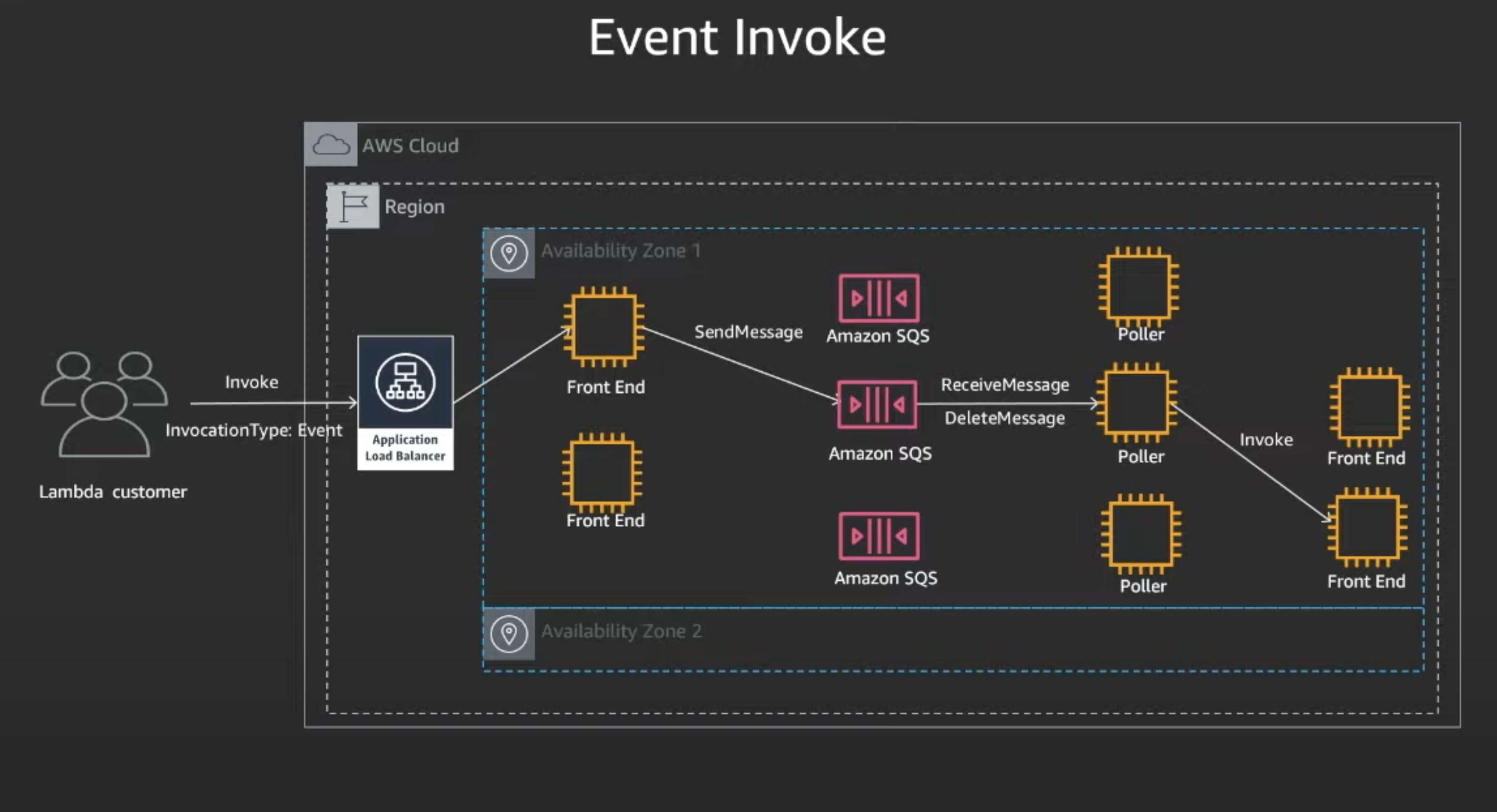
- Lambda customer calls invoke async, and calls front end
- Front End places message on a queue, and there are set of pollers assigned to the queues
- The assigned poller pulls message, and processes this message by placing message on the Front End Synchronous
- From there, it follows the Sync Invoke path covered earlier
Event Desitinations
So you can receive information from a async call, you can use event destinations. Event destinations provides customers visibility into results on an async invocation and provides visibiliy for a nmber of event sources including SQS, SNS, AWS Events, and Async Lambda.
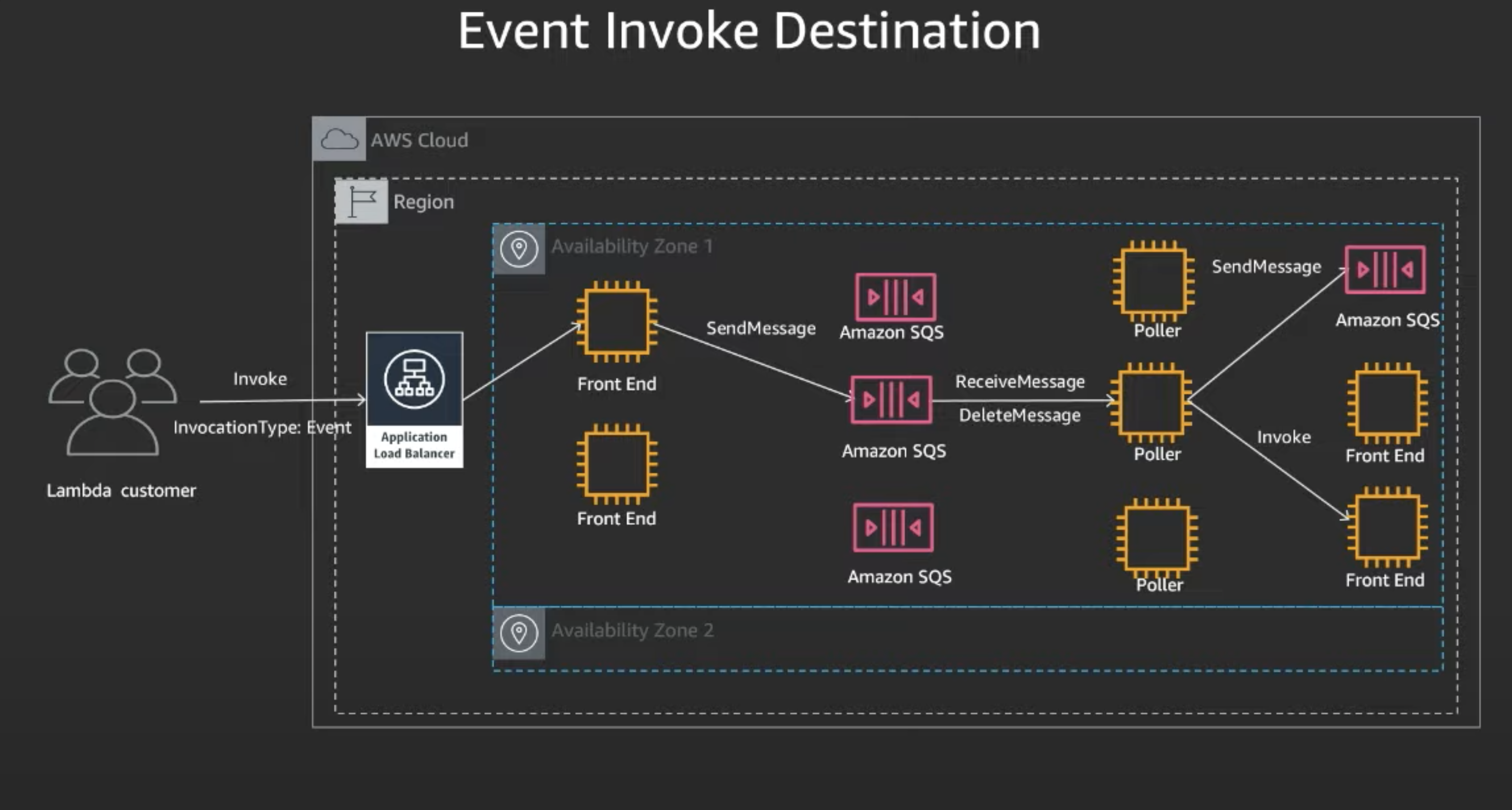
- Customer calls invoke async
- Same processes, up to Front-End
- The Sync invoke is processed. Whether the event is processed successfully or fails, in addition to deleting the message from the queue, the response is delivered to the event destination
Scaling Up and Down
How lambda dynamically adjusts to process incoming event volume? This is where the State manager and leasing service comes in. Statemanager is responsible for scaling up queues and associated pollers to keep up with processing of events up to the concurrency configuration and leasing service is responsible for acuiqring and realsing assignments to pollers.
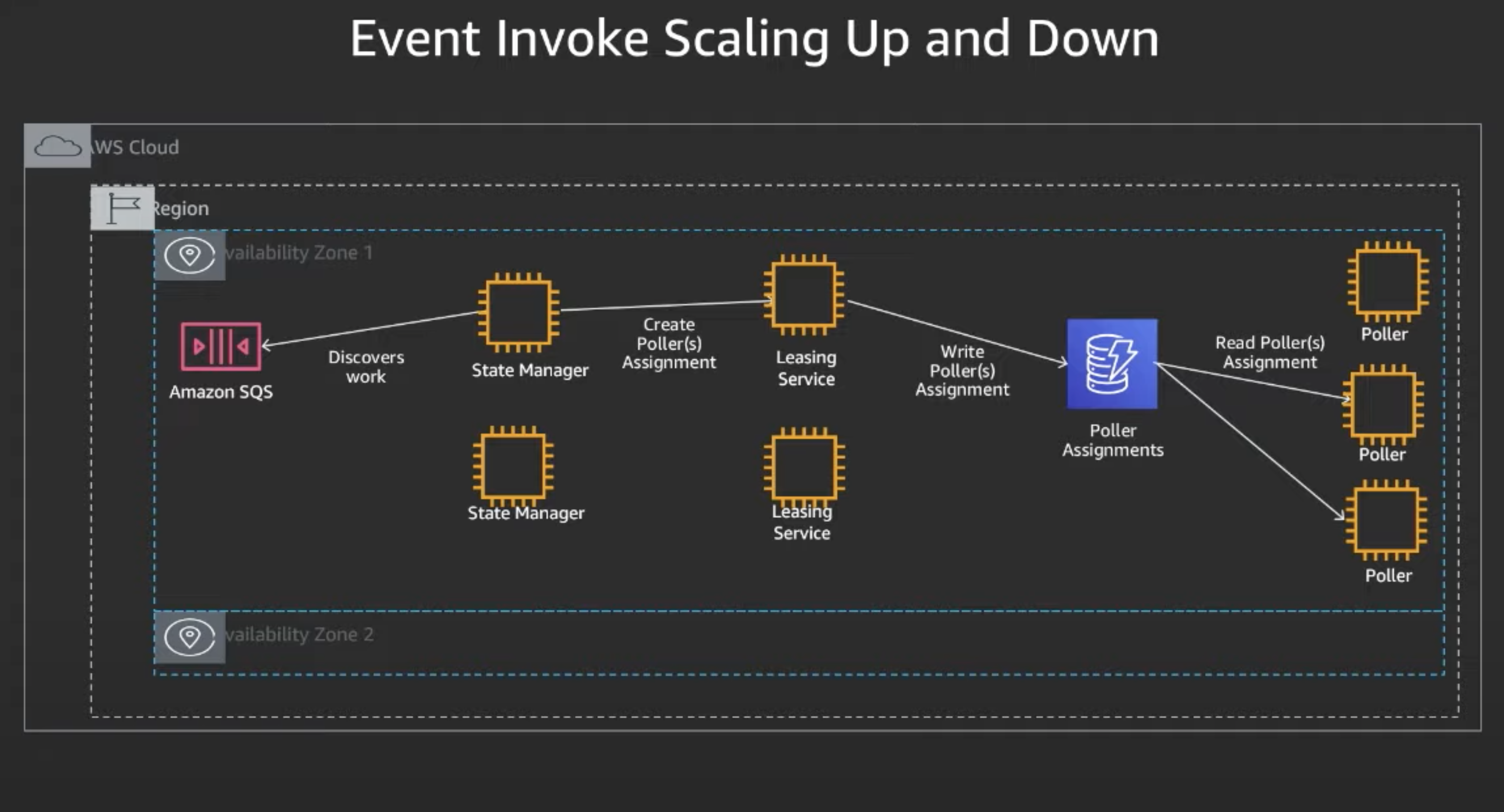
- State Manager discovers work on the queue. It will read the change and will create the Poller's assignment with the leasing service.
- If there is a large per function concurrency setting, state manager will create a new dedicated queue and
- If a small per function concurrency setting, it will use an existing queue
- The state manager ensures there is Poller redundancy by assigning multiple pollers to a given resources
- The Pollers read their assignment from the Poller Assigments Data
Handling Errors
Leasing service is responsible for periodically checking assignment health and making unhealthy assignments available for pollers, and detecting assignments that have not been heartbeated and giving that assignment to a new poller.
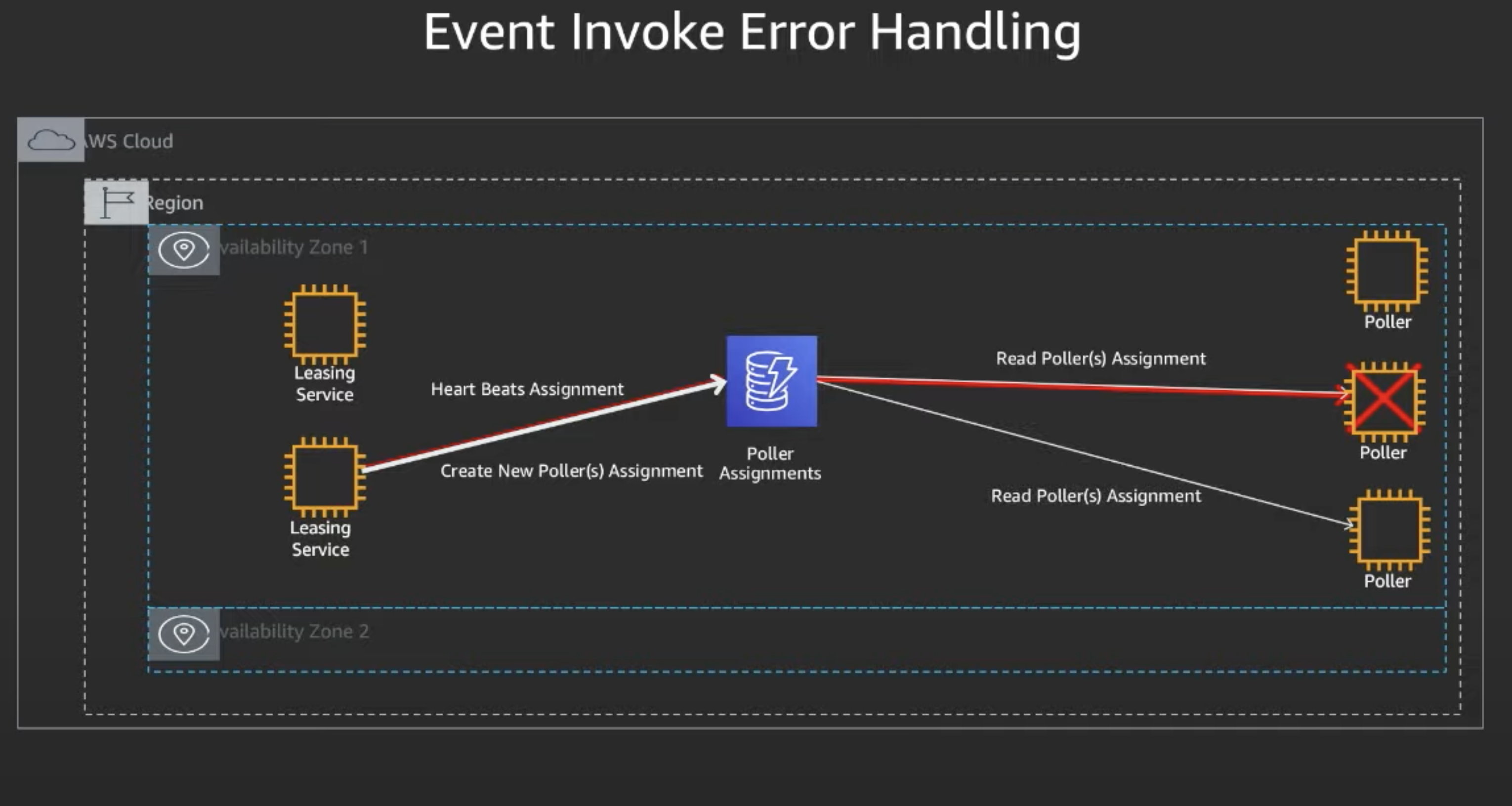
- A Poller is assigned to process an event source. The Poller stops processing its assignment
- The Leasing service checks assignment health, and sees an assignment that hasn't been heartbeated in the expected period
- THe Leasing service makes a new assignment making the unhealthy assignment available
- Another Poller picks up the assignment and starts processing the event source
Retry Policies
You are able to set your function's maximum age, so as to tell lambda to skip any invocations older than the configured number of seconds, and instead resume processing newer invocations.
- Maximum age can be 60 seconds to 6 hours.
- If you have backed up your queues with unwanted invocations, you can set this value to the lowest configured value, or DLQ, all back-logged invocations
- Attempts can be set to 0, 1 or 2
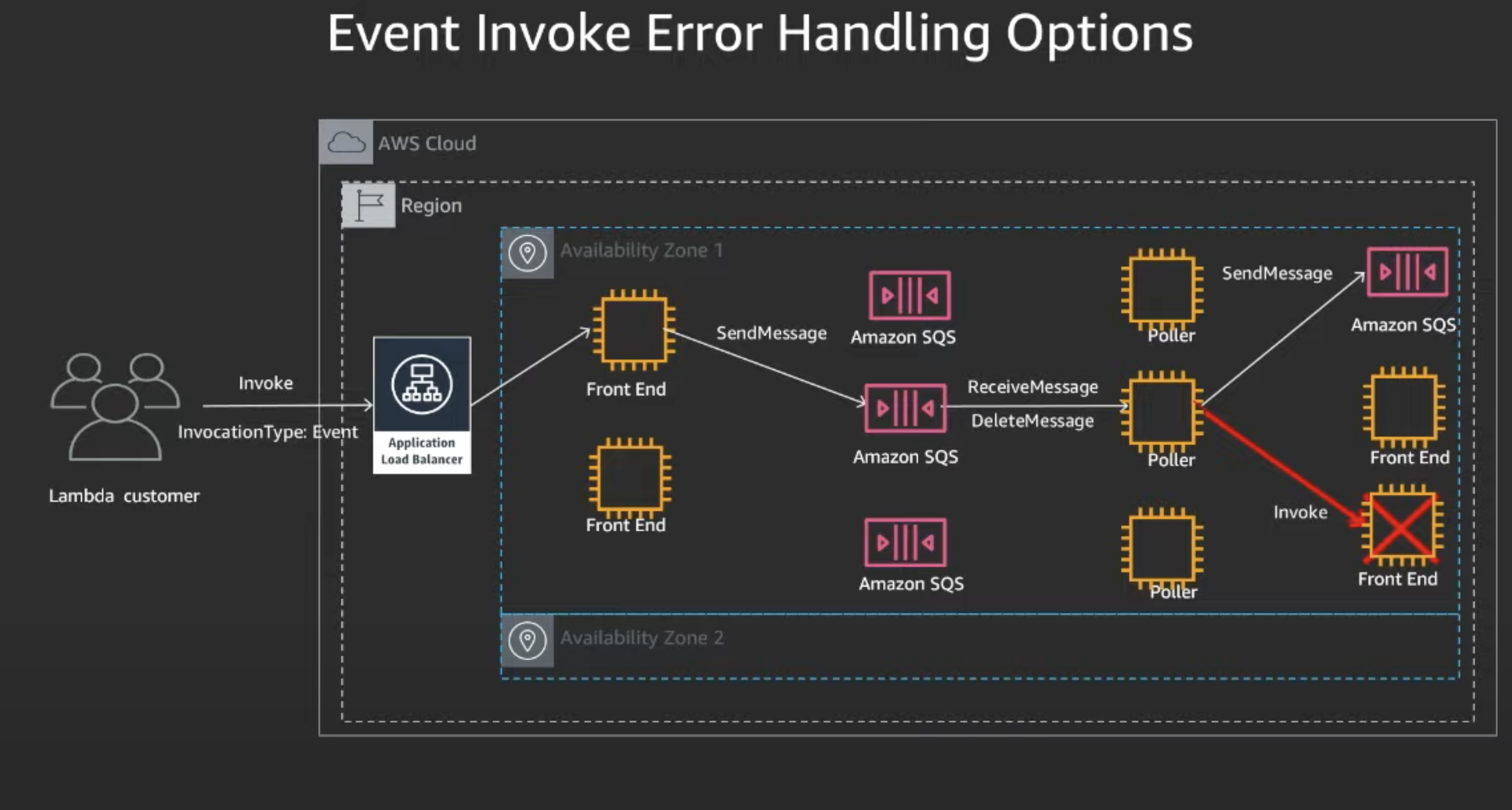
- Invoke called async, called front-end, placed on queue, etc..
- In this case, Front End Sync returns an error.
- Poller will observe retry policies, and wait, and try again
- If fails again, then places on a queue of failed invokes (if you have DLQ)
Stream Invoke
Used when hooked up to Kinesis streams or dynamoDB streams.
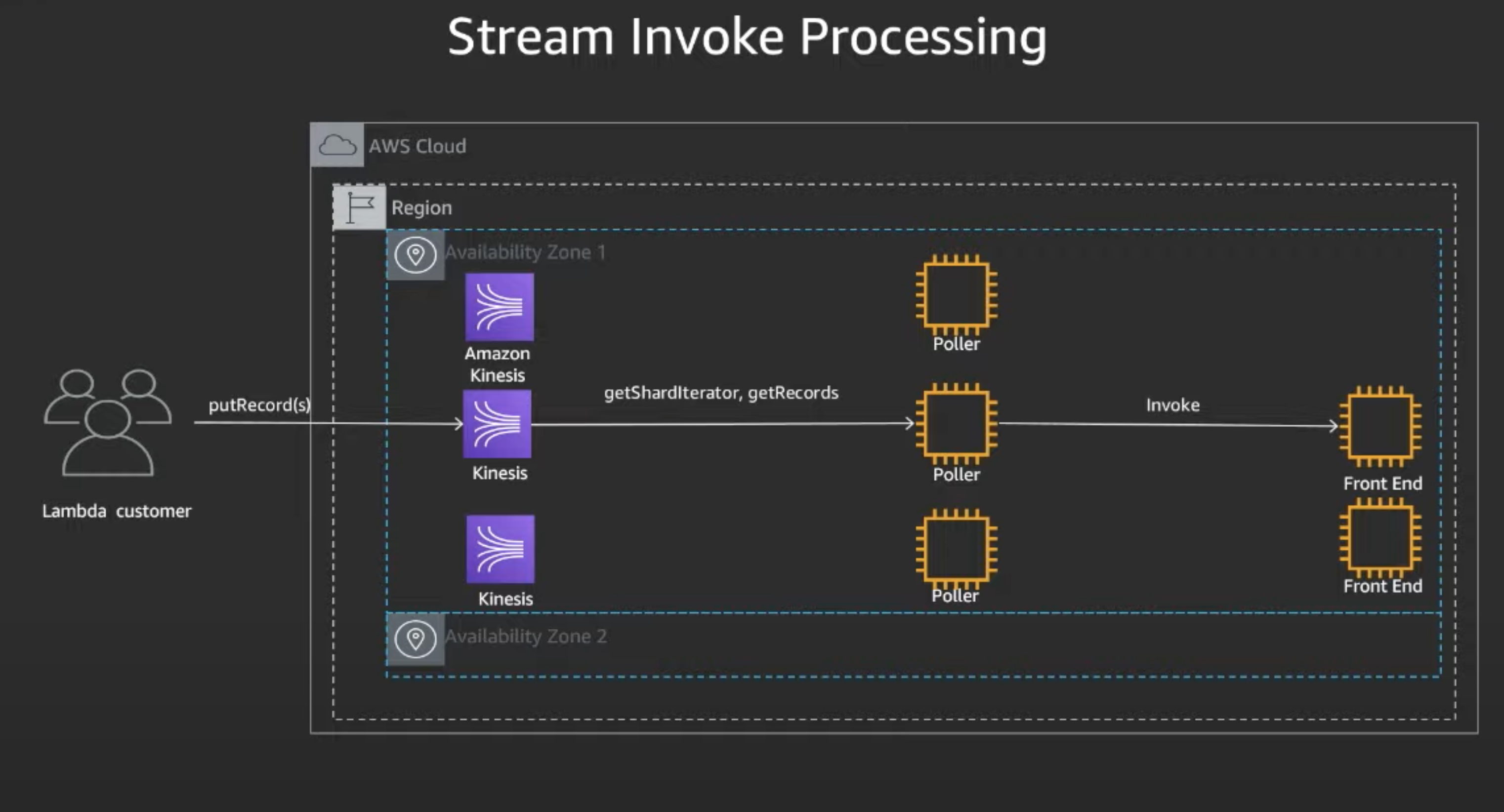
- Applications places one or more record on Kinesis
- Assigned Pollers receives messages from Kinesis
- Processes messages by placing them on Front End Synchronousnly
- Sync Invoke Path is then used to process event
How are streaming events established?
Similar to events, Pollers are mapped to Stream sources
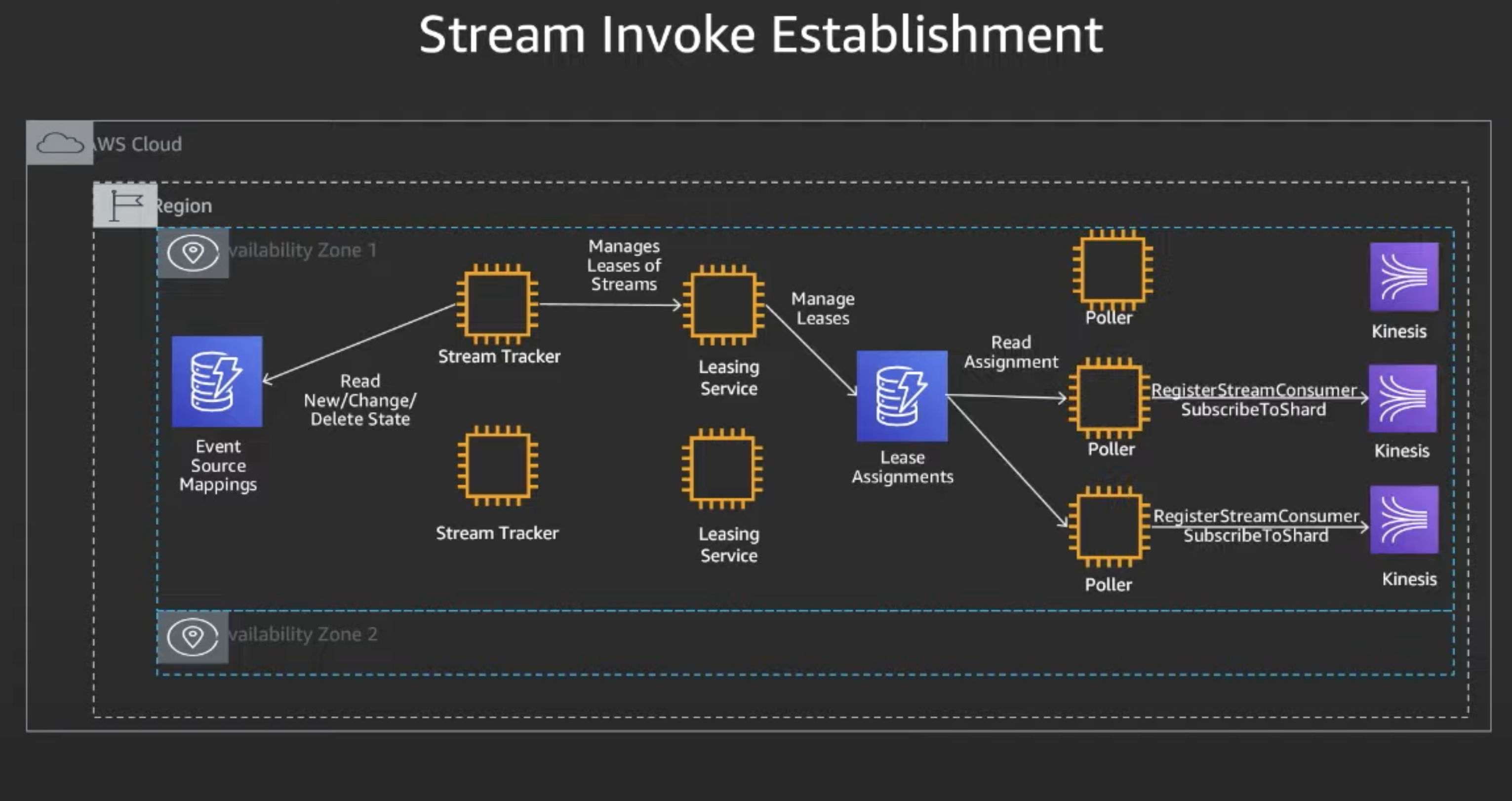
- Stream Tracker, like State Manager, reads changes on shard mappings
- Stream Tracker then uses leasing service to manage leases of streams
- Pollers reads assignments, and then subscribes to shards for Kinesis
Stream Invoke Scaling Up and Down
When a stream is enabled, we look at number of active shards to determine number of Pollers. If a stream has an in-shard, a poller is added. When Kinesis adds an additional shard, stream tracker triggers logic to caclulate concurrency required to process the stream. If additional shards are added, then stream tracker creates additional additional concurrency with the leasing service based on the number of additional shards. The number of shards are assigned evenly accross the pollers. The pollers have many threads to poll concurrently from the shards.
Parallelization factor: For streaming event sources with high-volume events, shards will fan-out processing, increasing lambda Parallelization while perserving ordering gurantees per partiion key.
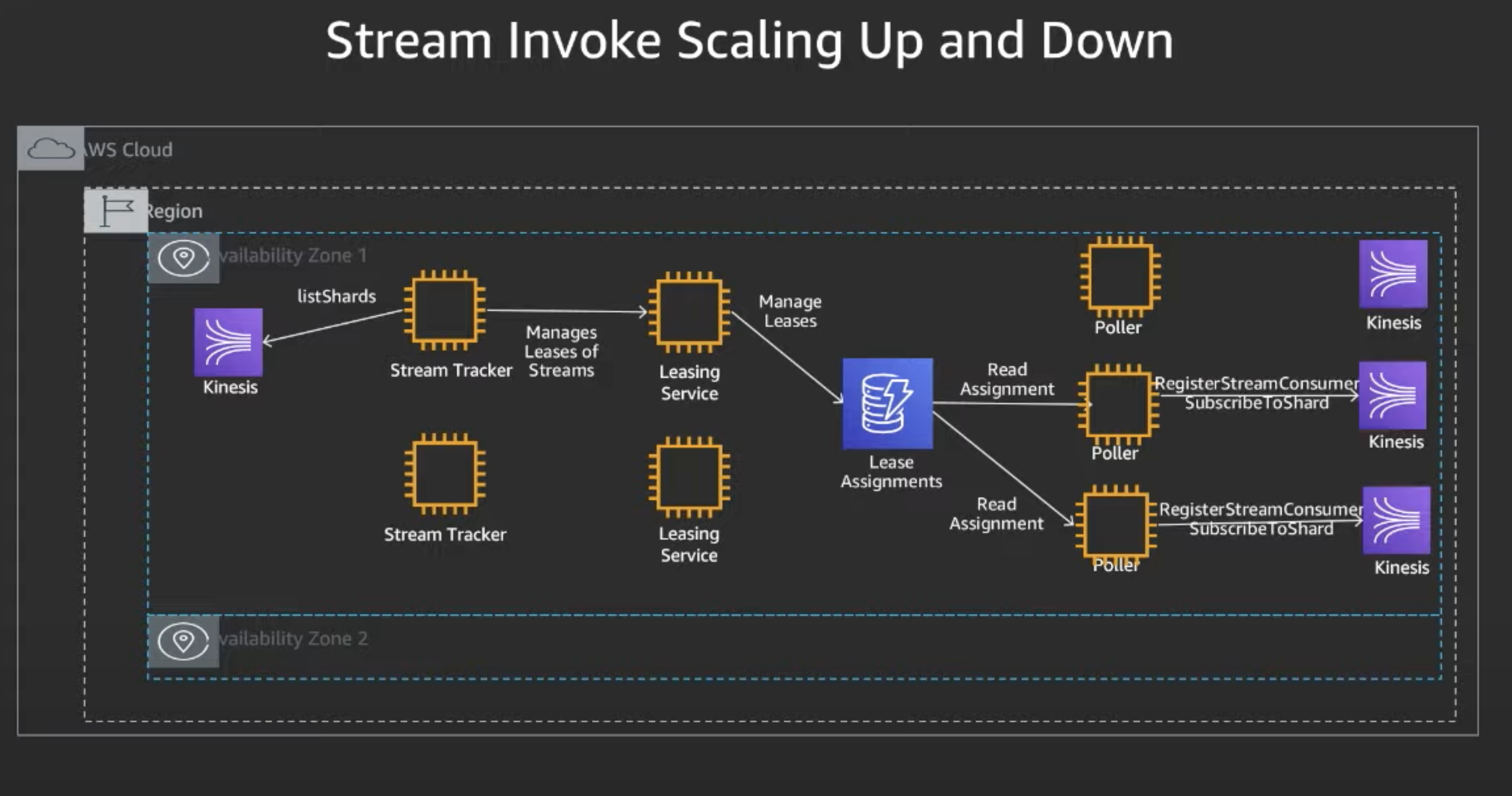
- Stream Tracker detects by calling listShards that there is a change in the number of shards requiring a scale up or down
- In reponse to this, ST will adjust number of leases with leasing services
- The Pollers retrieve their new assignment with desired number of pollers required to process required shard volume
- Poller than subscribes to the Sharding
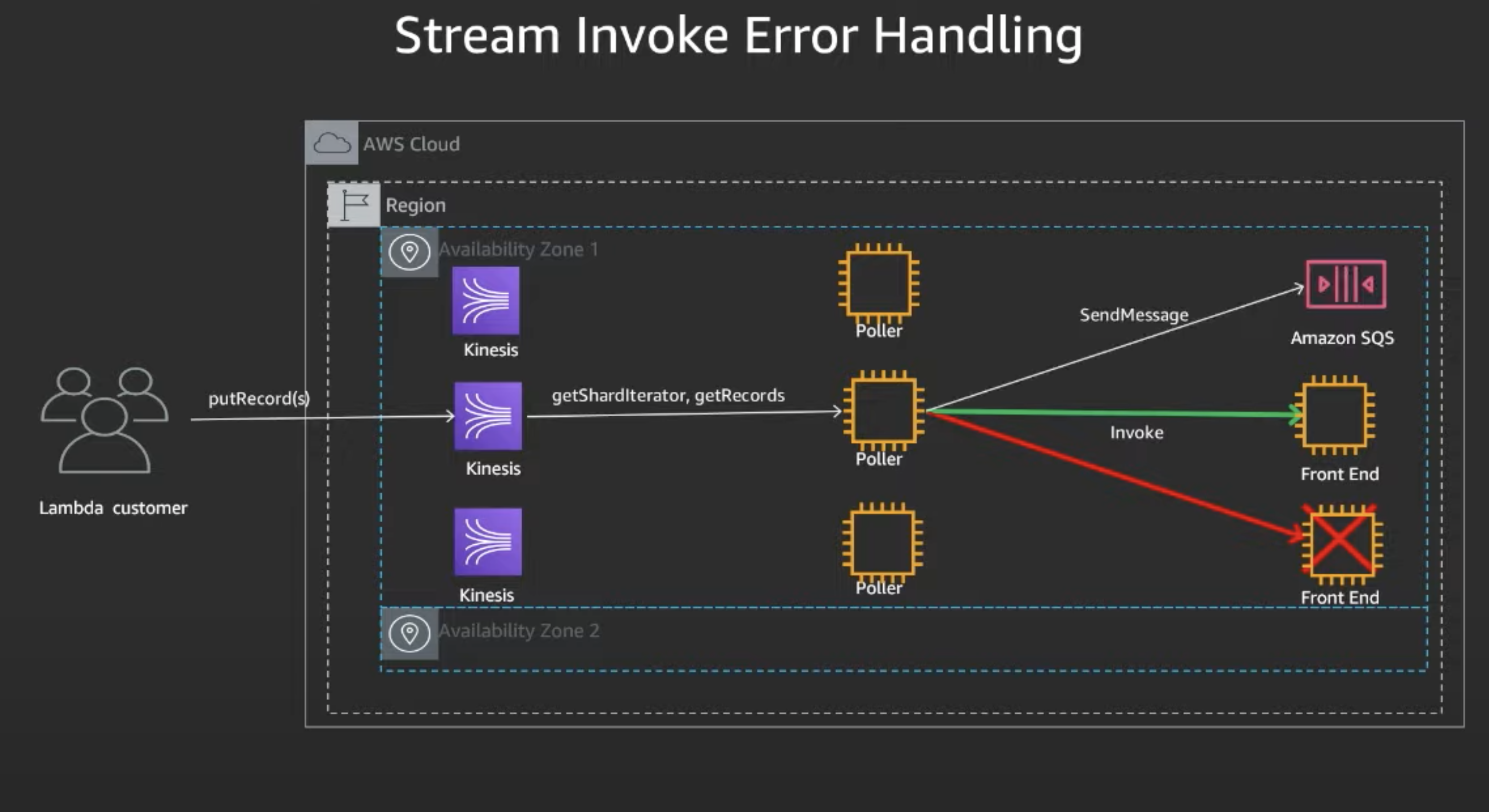
Stream Error Handling
Supports exponential backoff and DLQ support. Lambda processes streaming event sources with in-order guarantees and failed batches are retried until they expire. You can set max number of retries, record expiry time, and bisect batch on failure parameter to allow reties with a smaller number of records.
When the kinesis shard throughput exceeds lambda per function concurrency, then throttles occur with exponential backoff. Information about skipped records will be sent to a destinatoin specified by us, and supported destinations are SQS and SNS.
Rety, batch bisect rety, and DLQ
- Poller receives message from Kinesis and processes messages by placing them on Front End on Synchronousnly
- Front End fails, Poller splits batch in two and retries with two batches, and this time if one batch exceeds and other fails, Poller writes failed batch info to the configured DLQ.
Lambda Provisioned Concurrency
This lets you keep your functions intialized and ready to respond in milliseconds within double-digit.
Lambda Best Practices and 'How-To'
Import only required dependency from AWS SDK
import {DocumentClient} from 'aws-sdk/clients/dynamodb'
DON'T DO:
import aws from 'aws-sdk'
const DocumentClient = aws.dynamodb.DocumentClient
Invoke HTTP from AWS Lambda without Waiting
Wait for request transmission, not for response. Waiting for request to be sent makes sure the request gets sent before lambda exists. If we don't need the respond, don't wait for it, instead only wait for the req.end.
import https from 'https'
import URL from 'url'
async function request(url, data) {
return new Promise((resolve, reject) => {
let req = https.request(URL.parse(url))
req.write(data)
req.end(null, null, () => {
/* Request has been fully sent */
resolve(req)
})
})
}
export default async function (event, context) {
await request('https://example.com', metrics)
return 'done'
}
Concurrency
https://aws.amazon.com/blogs/compute/managing-aws-lambda-function-concurrency/
Increase Lambda speed
Reduce bundle size
Do not import the whole AWS SDK like so:
import {CloudFront, Lambda} from 'aws-sdk'
Instead, do it like this:
import CloudFront from 'aws-sdk/clients/cloudfront'
import Lambda from 'aws-sdk/clients/lambda'
Goal is to significantly reduce the final bundle size. This can be done with other packages as well.
Use Webpack
Webpack is recommended so only code that will be used goes into the bundle.
5 ways to make functions faster AWS Lambda performance optimization
Cold-start performance.
Learn about cold starts
Take-aways:
- Function size (and node_modules size) impacts cold-starts significantly. Above 14MBs and cold-start is > 2 seconds. If function is 35MB, cold-start is 3-6s.
- Docker image size does not seem to influence the cold start duration.
Serverless-side rendering
When possible, execute code in parallel
Sometimes you can avoid doing things in series. Don't do:
Example 1
const operations = [a, b, c, d, e]
for (let i = 0; i < operations.length; i++) {
await operations[i]() // 100ms operation.
}
Instead do it in parallel:
const operations = [a, b, c, d, e]
const promises = []
for (let i = 0; i < operations.length; i++) {
promises.push(operations[i]())
}
await Promise.all(promises) // 100ms operation.
Example 2
Don't do:
async function fetchAllCounts(users) {
const counts = []
for (let i = 0; i < users.length; i++) {
const username = users[i]
const count = await fetchPublicReposCount(username)
counts.push(count)
}
return counts
}
Instead do:
async function fetchAllCounts(users) {
const promises = users.map(async (username) => {
const count = await fetchPublicReposCount(username)
return count
})
return Promise.all(promises)
}
In case you want to do things, in batches. Check out p-map for limited concurrency
If you have multiple API calls that don't need to be awaited to continue execution, you can also do the following:
async run(loads: [any]) {
const promises: [Promise<any>] = []
const result = loads.map(async load => {
const {loadId, truckNumber, _id} = load
const number: [keyof typeof trucks] = truckNumber.match(numberPattern)
let truck = trucks[number[0]]
const response = await fetch('https://my54.geotab.com/apiv1/', {
method: 'POST',
body: this.getBody(truck)
})
let {result} = await response.json()
if (result) {
let geoResponse = await geocodingService.reverse(result[0].latitude, result[0].longitude)
if (geoResponse) {
let {road, city, country, state, postcode} = geoResponse
const obj: ghettoDTO = this.getLocationObj(road, city, country, state, postcode, result)
promises.push(loadRepo.updateLocation(_id, obj))
promises.push(loadRepo.updateLoadLocation(_id, obj))
}
}
return true
})
await Promise.all(promises) // 1448 and 1491 ms when this is in .map
// 1229ms, 1060ms, and 1202 ms when here outside the .map
return Promise.all(result)
}
Enable HTTP Keep-alive
https://medium.com/predict/lambda-optimization-tip-enable-http-keep-alive-ef7aa7880554
Set this environment variable:
AWS_NODEJS_CONNECTION_REUSE_ENABLED to 1